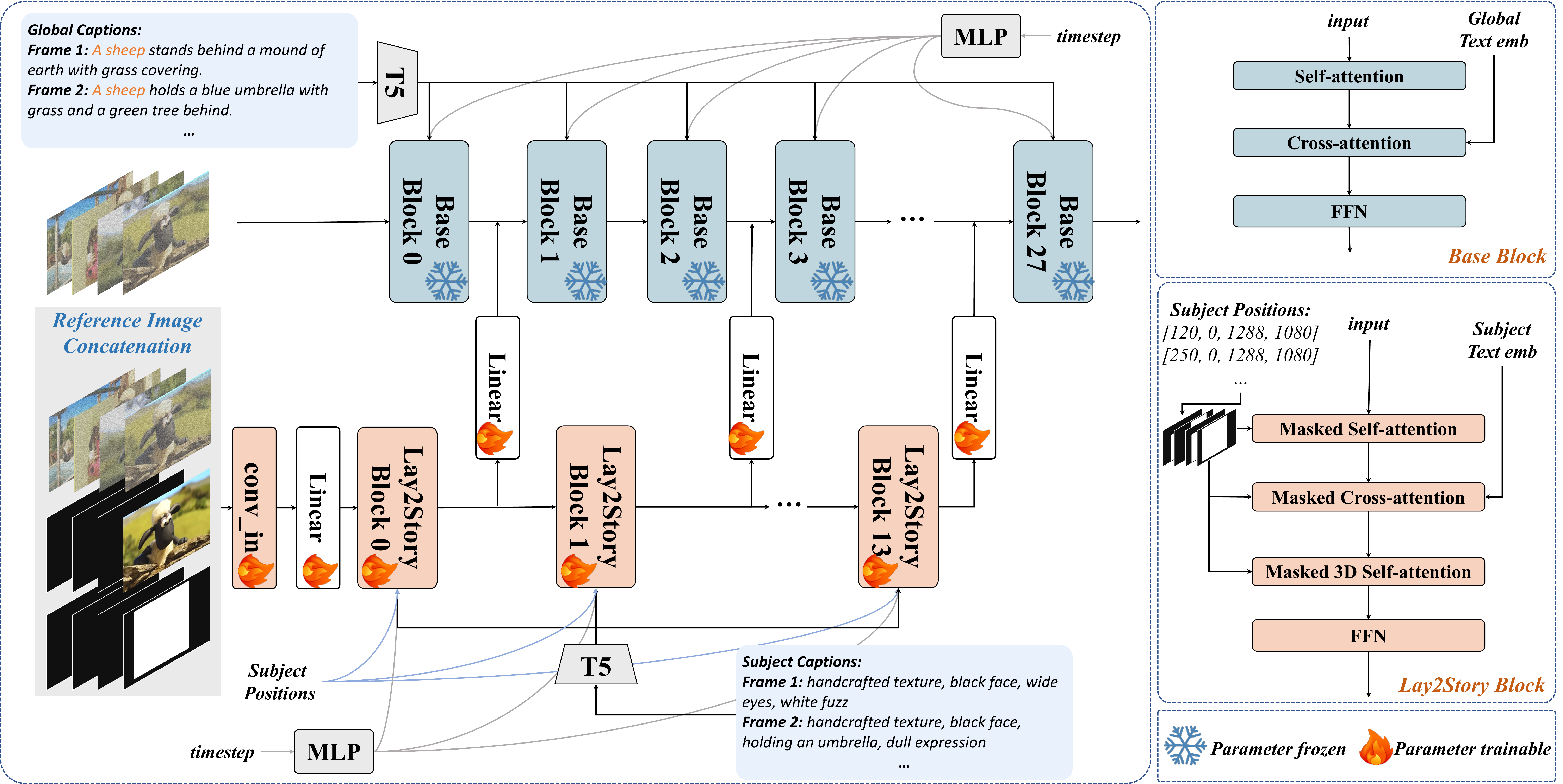
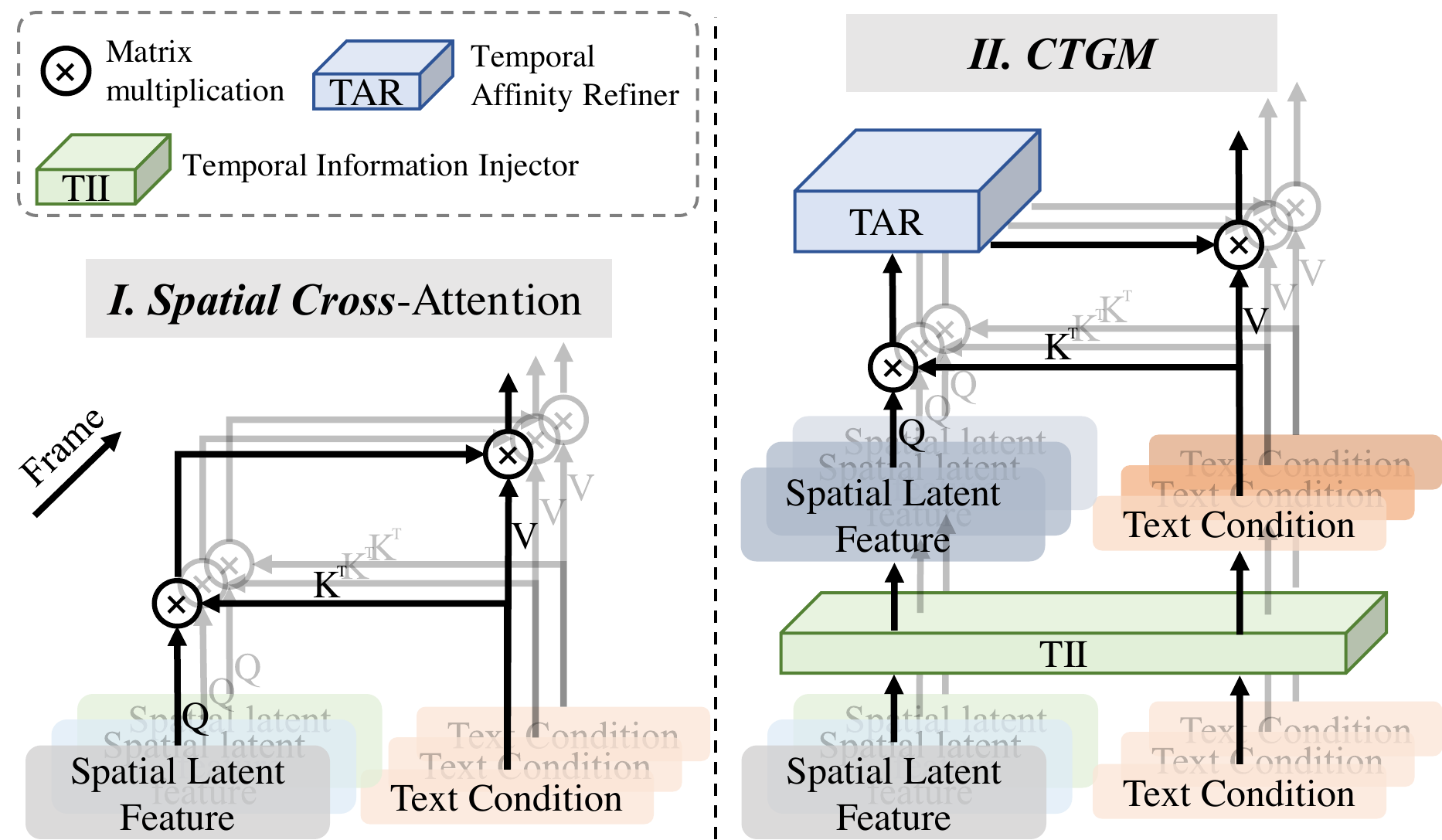
FancyVideo — Cross-frame Textual Guidance
痛点:AnimateDiff 等 T2V 把同一段 text embedding 复制到每一帧做 spatial cross-attention → [verb] 关注区几乎不变 → 动作弱、长视频更明显。
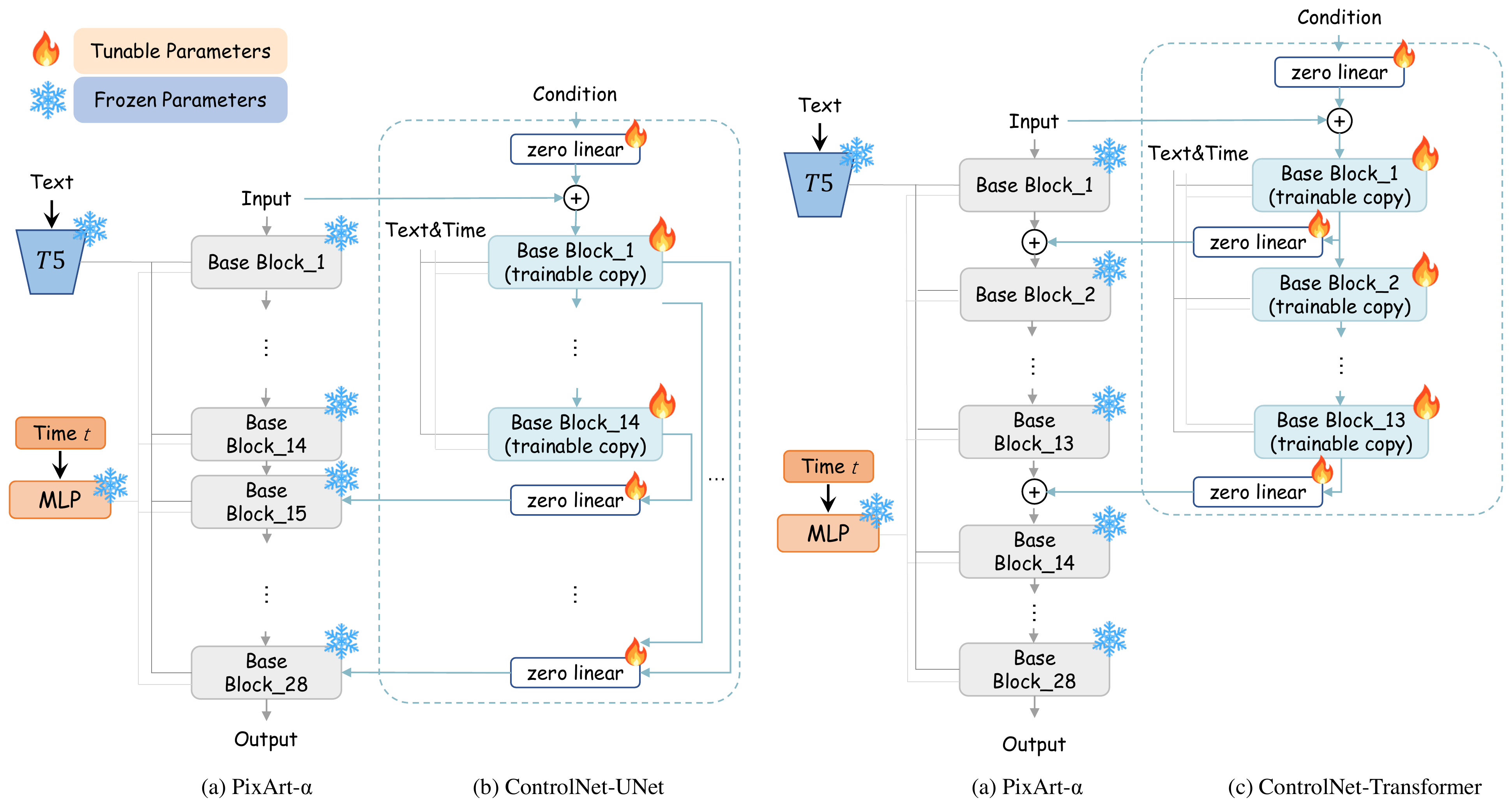
PixArt-δ — Fast and Controllable Image Generation with LCM
PixArt-α 已是高效 DiT 文生图基座;PixArt-δ 在其上叠两层能力:LCM 蒸馏把采样从 14 步压到 2–4 步,A100 上 0.5s/1024px(相对 α 约 7× 加速);ControlNet-Transformer 把边缘/深度等条件注入 DiT,实现细粒度可控生成。
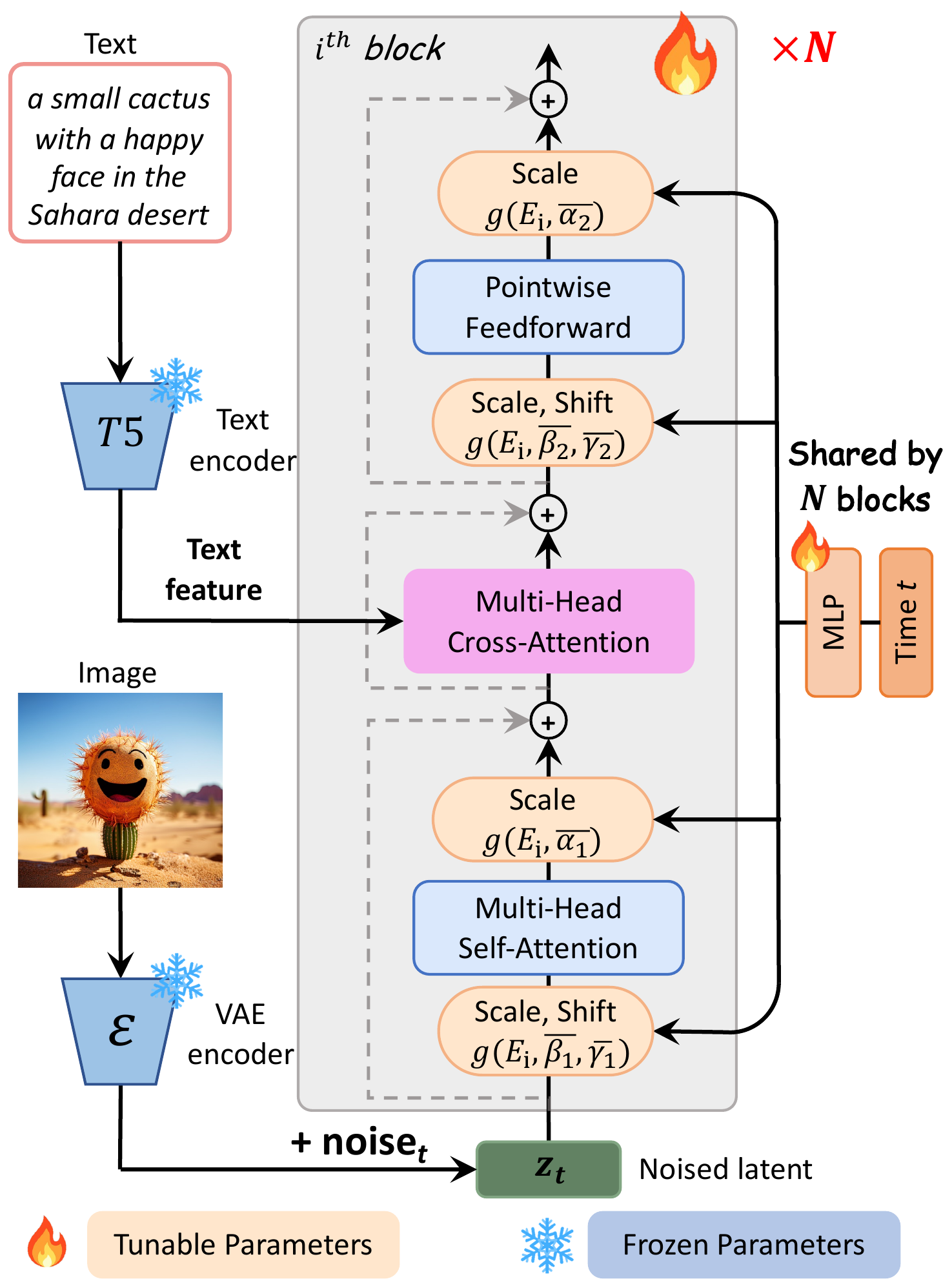
PixArt-α — Fast Training DiT for T2I
文生图(T2I)训练极贵——Stable Diffusion 1.5 级别模型常需数百万 GPU 时。PixArt-α 的核心思路是「分阶段解耦」:不要一上来就 1024px + 文本 + 美学一起学,而是拆成三步——先学像素依赖(低分辨率、无文本),再学文图对齐,最后学美学与高分辨率。每一步只解决一个子问题,训练更稳、更省。
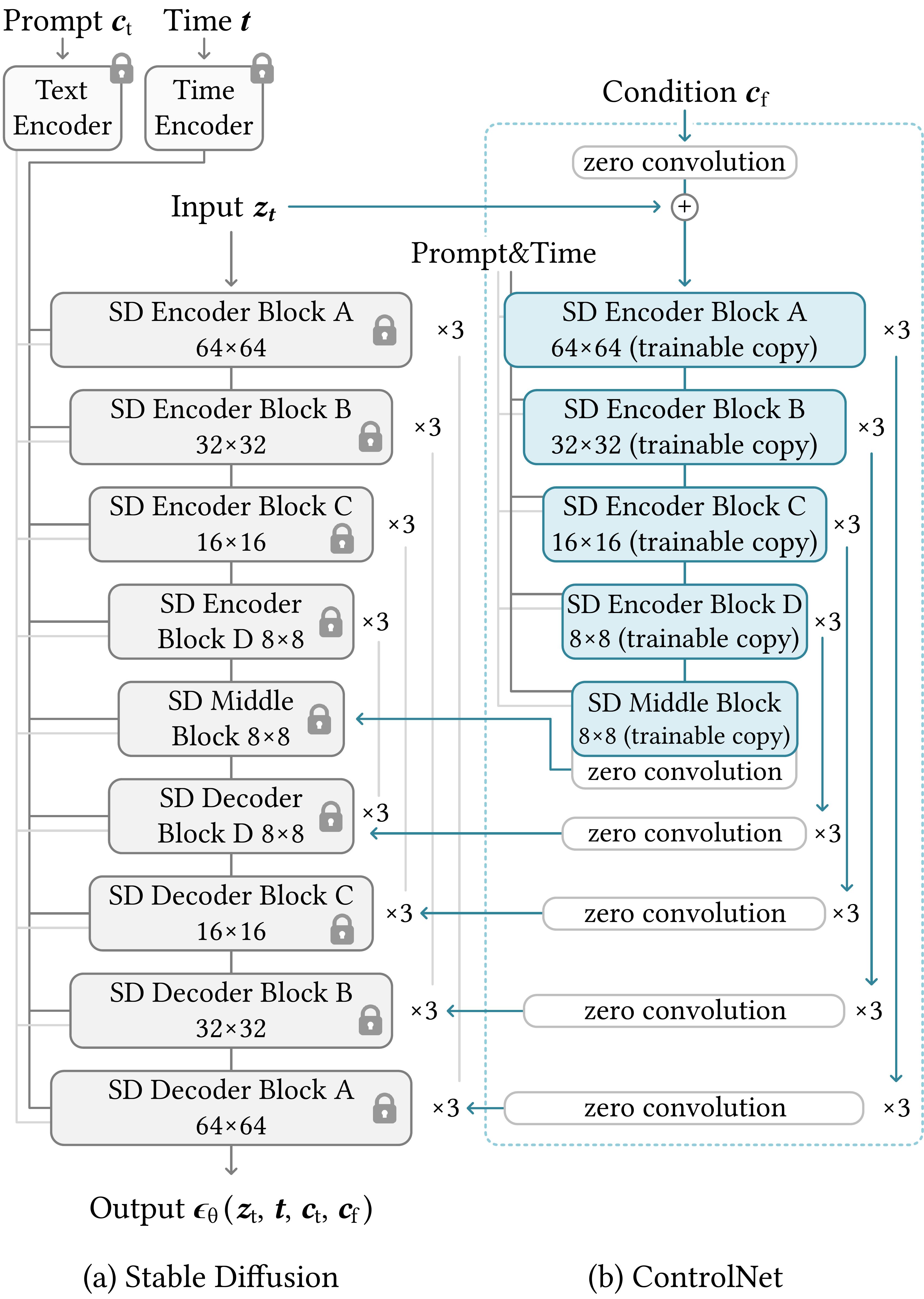
ControlNet — Adding Conditional Control to Text-to-Image Diffusion Models
大扩散模型(如 Stable Diffusion)只会听文字,难精确控构图、姿态、边缘。ControlNet = 锁住原 U-Net 权重 + 复制可训练支路,用 zero-init 1×1 卷积渐进注入条件,不破坏预训练能力。可训 Canny / depth / pose / seg 等;小数据集也稳;「sudden convergence」现象——几百步后 loss 突然下降、条件控制突然学会。
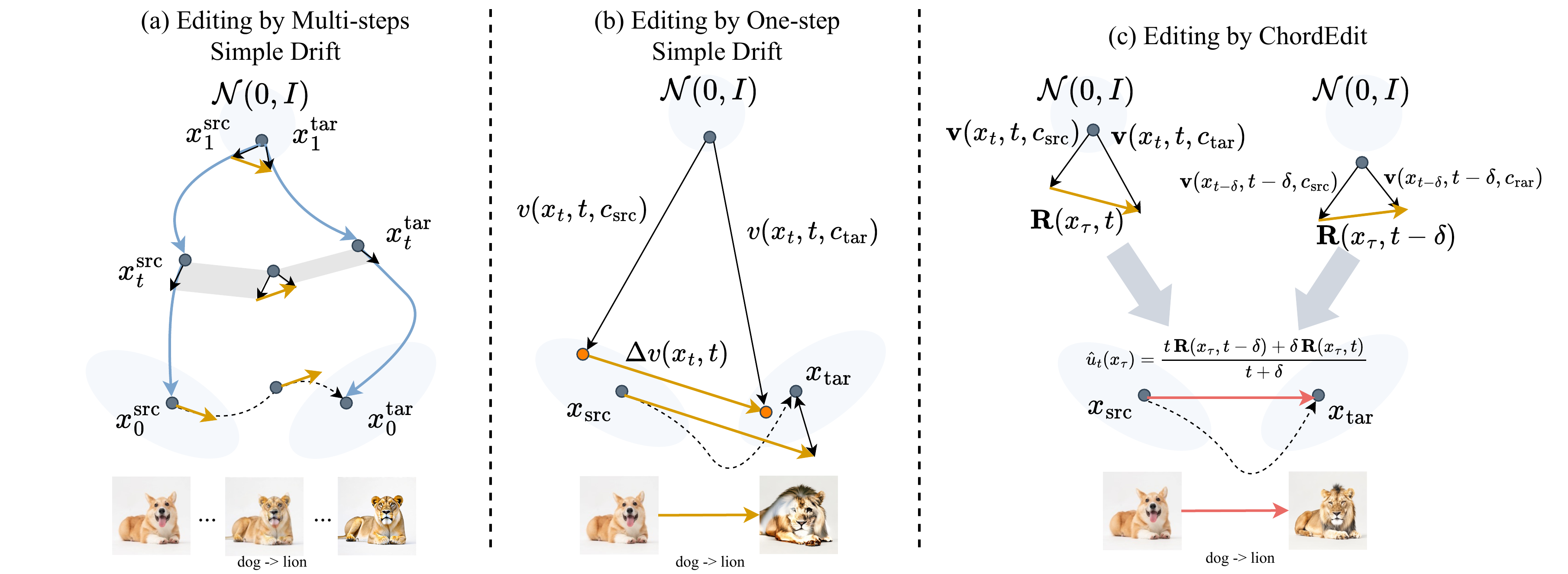
ChordEdit — One-Step Low-Energy Transport for Image Editing
一步文生图模型(如 SD-Turbo、SwiftBrush-v2、InstaFlow)把原本需要几十步的扩散蒸馏成一次前向就能出图——合成速度极快,自然让人期待「实时编辑」。但把传统编辑套路(源/目标 prompt 的 drift 差分)硬塞进一步模型会彻底翻车:物体严重扭曲、背景碎裂——因为 naive 编辑场是两个大幅度、发散轨迹的算术差,能量高、方差大,单步大积分误差累积致命。
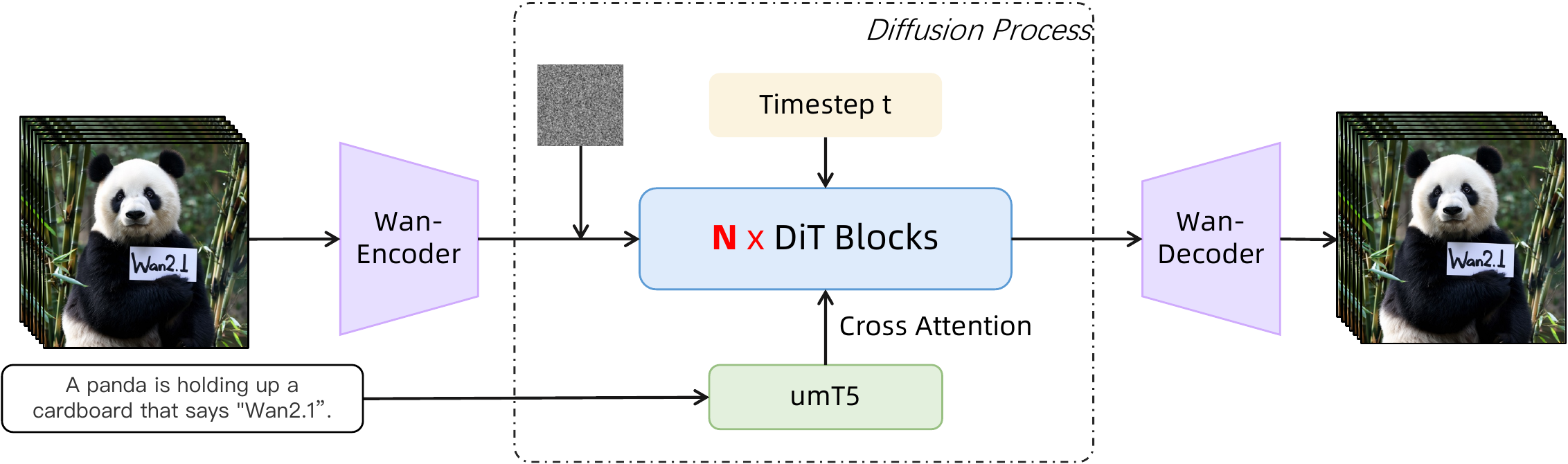
Wan2.1 — Open and Advanced Large-Scale Video Generative Models
开源文生视频(HunyuanVideo、CogVideoX、Mochi)与闭源 Sora 仍有性能/能力/效率差距。Wan2.1 = 阿里 Wan 团队全栈技术报告 + 开源:Wan-VAE(3D 因果、4×8×8 压缩、127M 参数 + feature cache 流式编解码)+ DiT + Flow Matching(umT5 文本、3D RoPE 全时空注意力、共享 timestep MLP 省 25% 参)+ 十亿级图文视频预训练(256→480→720 分辨率课程)+ Wan-Bench 自动评测。提供 1.3B(8.19GB VRAM 消费级)与 14B 两档;覆盖 T2V/I2…
Recent
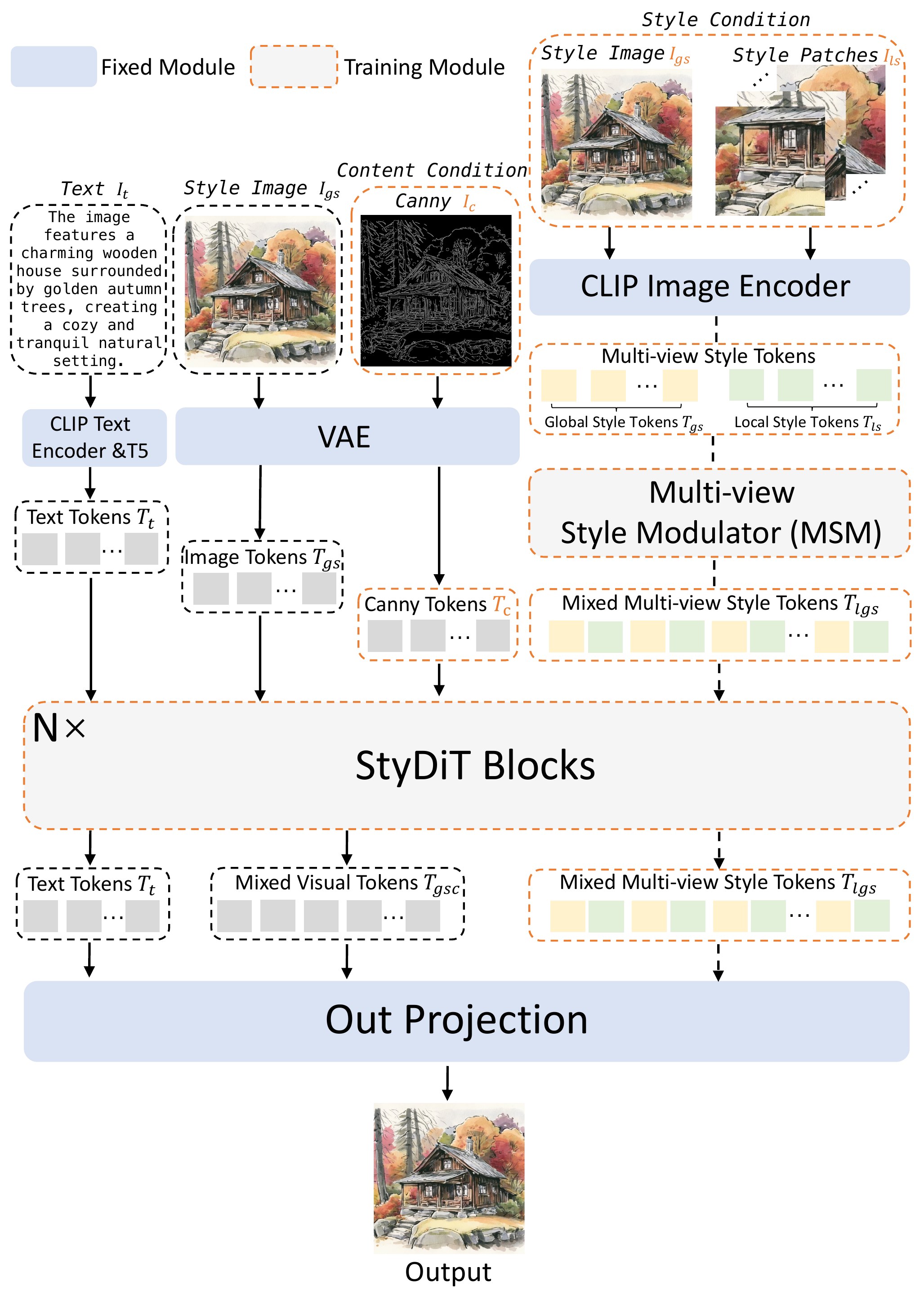
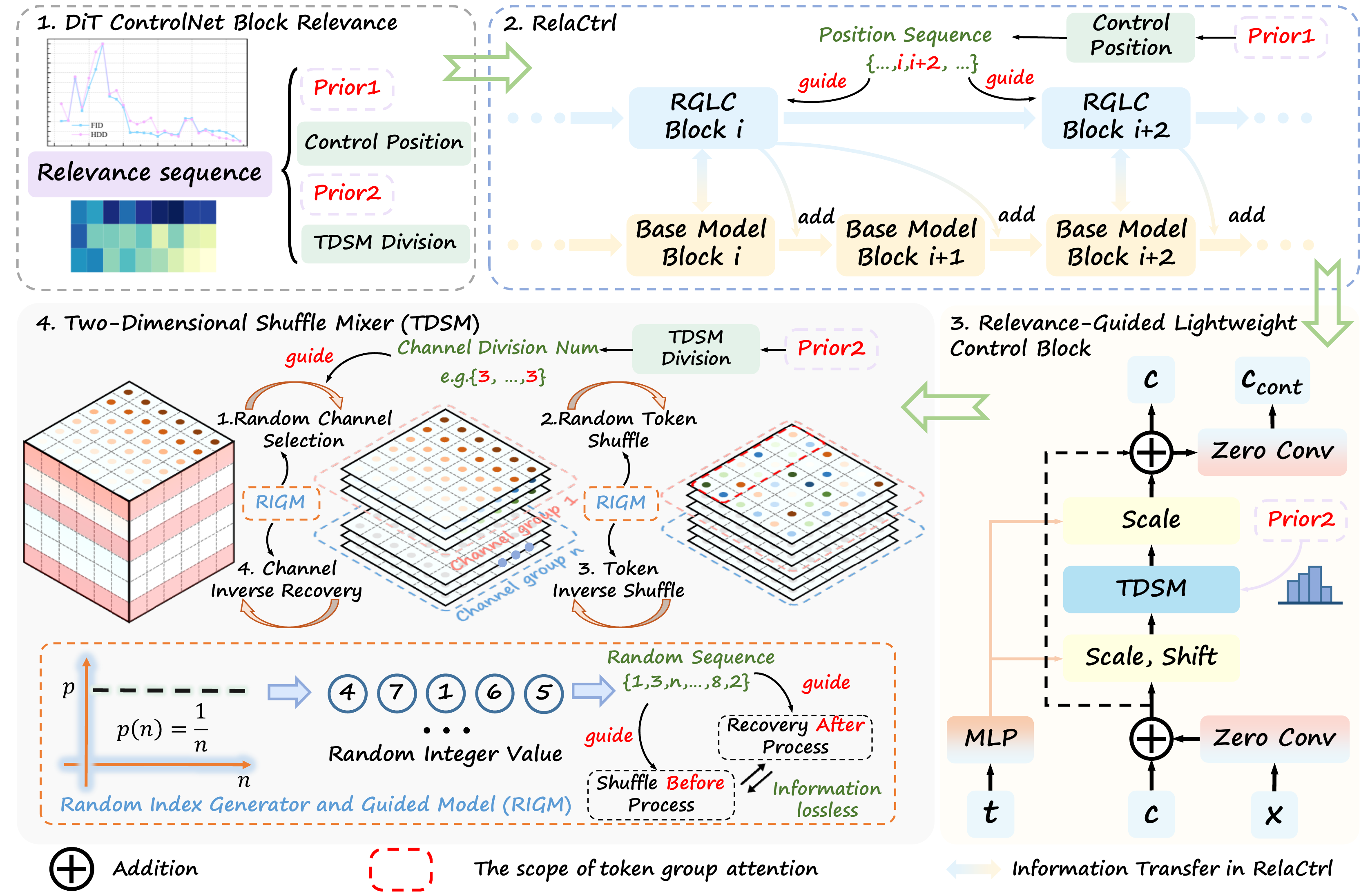
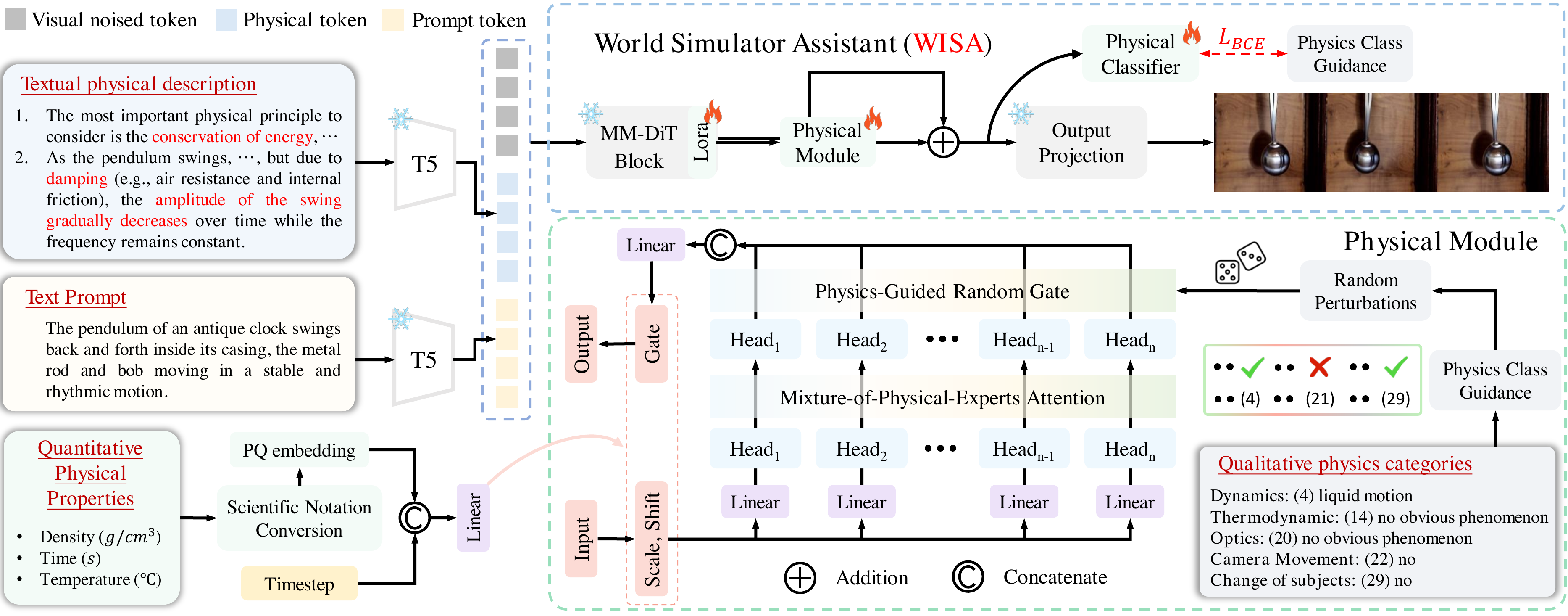
Recent