🎮 费曼一分钟
问题:DiT 全局 self-attention 对视觉 token 是 $O(N^2)$,高分辨率图/长视频算不动;且 PixArt 注意力图显示同窗口内 token 对远处位置注意力几乎一样——大量全局注意力是冗余的。
PT-DiT:每个时空窗口做 平均池化 得一个 proxy token;proxy 之间做 self-attention(GIIM)建模全局,再 cross-attention 广播回全部 latent;局部细节用 Swin 式 window + shift-window attention(TCM)补纹理。
Qihoo-T2X 家族:同一 PT-DiT 骨架 → T2I / T2V / T2MV(文生图、文生视频、文生多视角)。压缩比随分辨率变:(1,2,2)→(1,4,4)→(1,8,8)→(1,16,16)。
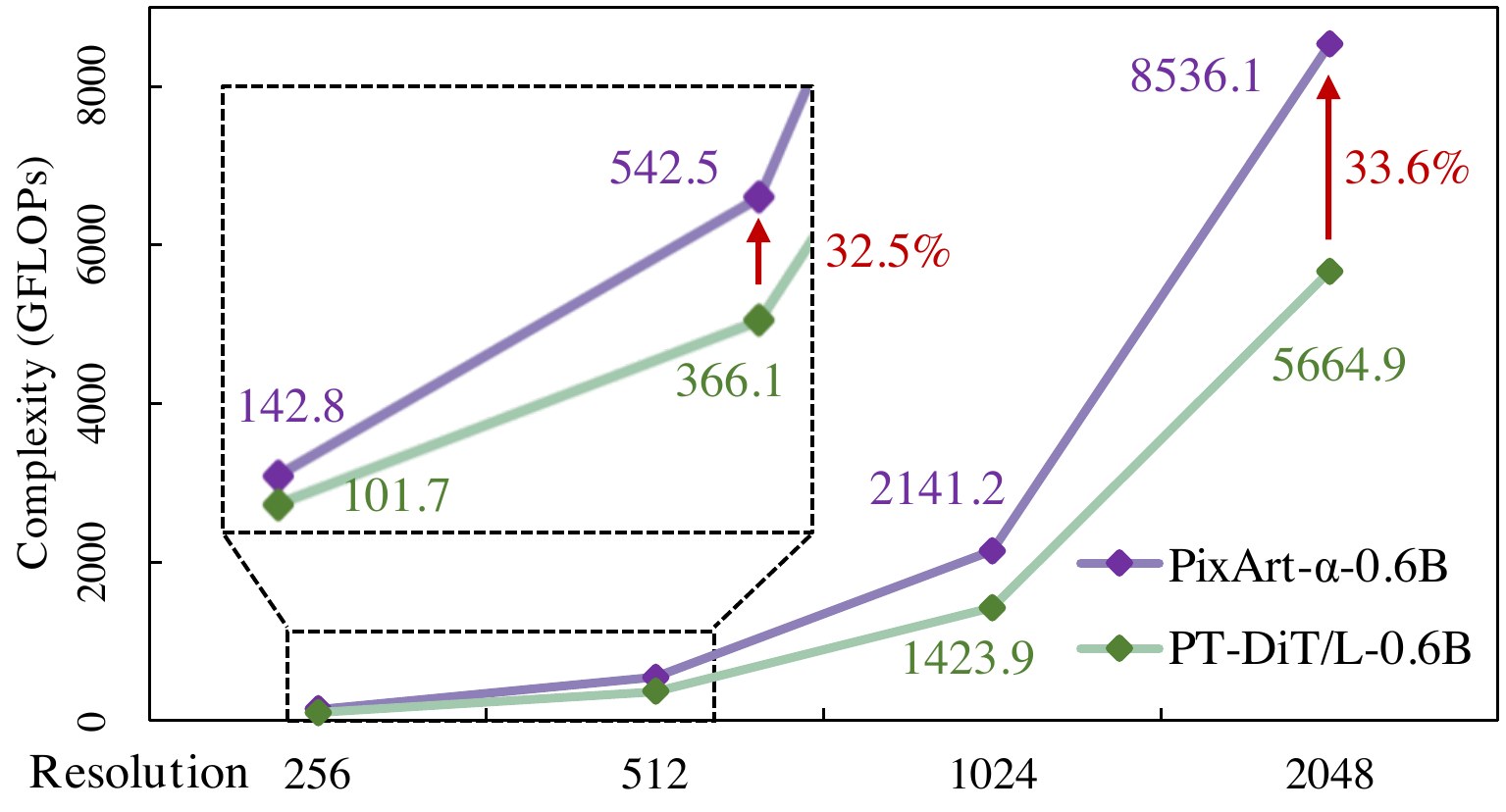
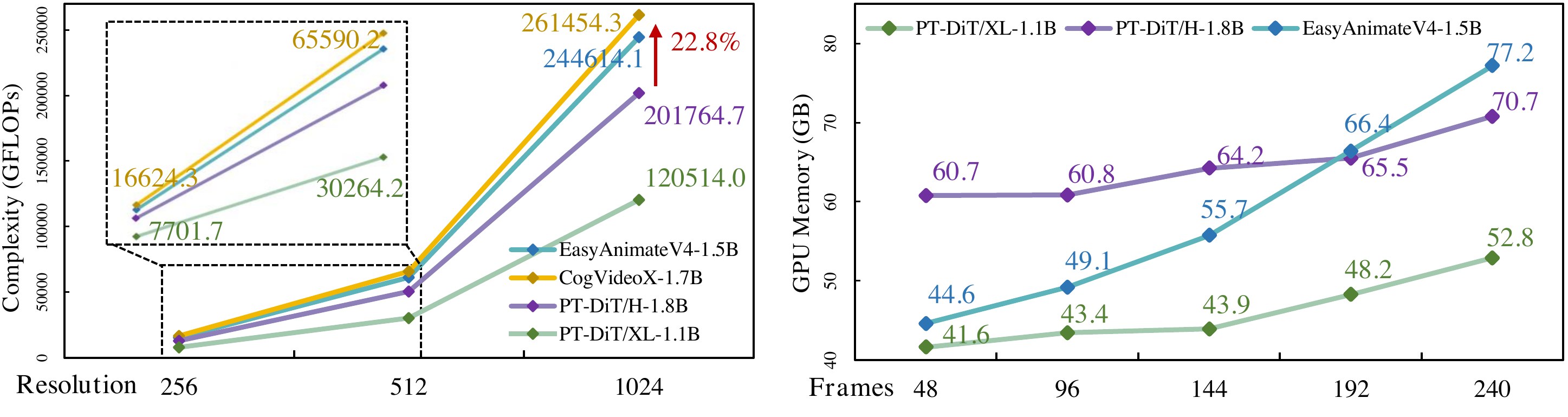
效率:同参数量下 GFLOPs ≈ DiT 的 51%、PixArt-α 的 66%;T2V 上 FVD 384(DiT 系 SOTA),显存随帧数增长远慢于 EasyAnimateV4 全 3D attention。
Abstract
Global self-attention in DiT is redundant because visual information is sparse/repetitive; tokens in the same window have similar attention to distant locations.
PT-DiT: sparse representative (proxy) token attention — average per spatial-temporal window → proxy SA → cross-attn to all latents; plus window/shift-window attention for detail.
Qihoo-T2X: T2I, T2V, T2MV. ~49% complexity reduction vs DiT, ~34% vs PixArt-α.
视觉信息稀疏重复 → 全局注意力冗余;同窗口 token 对远处注意力图几乎相同。
用窗口平均 proxy token 做稀疏全局建模 + cross-attn 注入;window/shift-window 补局部纹理。
推出 Qihoo-T2I/V/MV;算力显著低于 DiT/PixArt-α。
DAM 用 mediator token 代理 Q/K;本文用空间先验平均得 proxy,再 GIIM+TCM 分工。比「直接砍 attention 矩阵」更保留局部邻域差异(TCM 负责)。
📄 Figure 1:Qihoo-T2I 样例

1. Introduction
Sora/Vidu/CogVideoX/Lumina-T2X 等证明 DiT 可扩展,但全局 attention $O(N^2)$ 阻碍高分辨率与长视频。
3D full attention 强于 2D+1D temporal,但算力爆炸;2D+1D 时空建模弱。
Key observation (Fig. attn): within a $4\times4$ window, attention to distant tokens is nearly identical across window tokens; neighboring tokens differ — dense long-range SA is redundant, local SA is critical.
DiT 质量好但全局注意力贵;全 3D attention 强但不可扩展。
核心观察:同窗口内 token 对「远处」注意力几乎一样 → 可用少量 proxy 代表;对「近处」差异大 → 需 window attention。
GIIM = 廉价全局(proxy SA + cross);TCM = 昂贵但局部的 window/shift-window。与 RelaCtrl「按层选条件」正交——本文是按空间稀疏化 token 参与全局 attention。
📄 Figure 2:PixArt-α 注意力冗余可视化
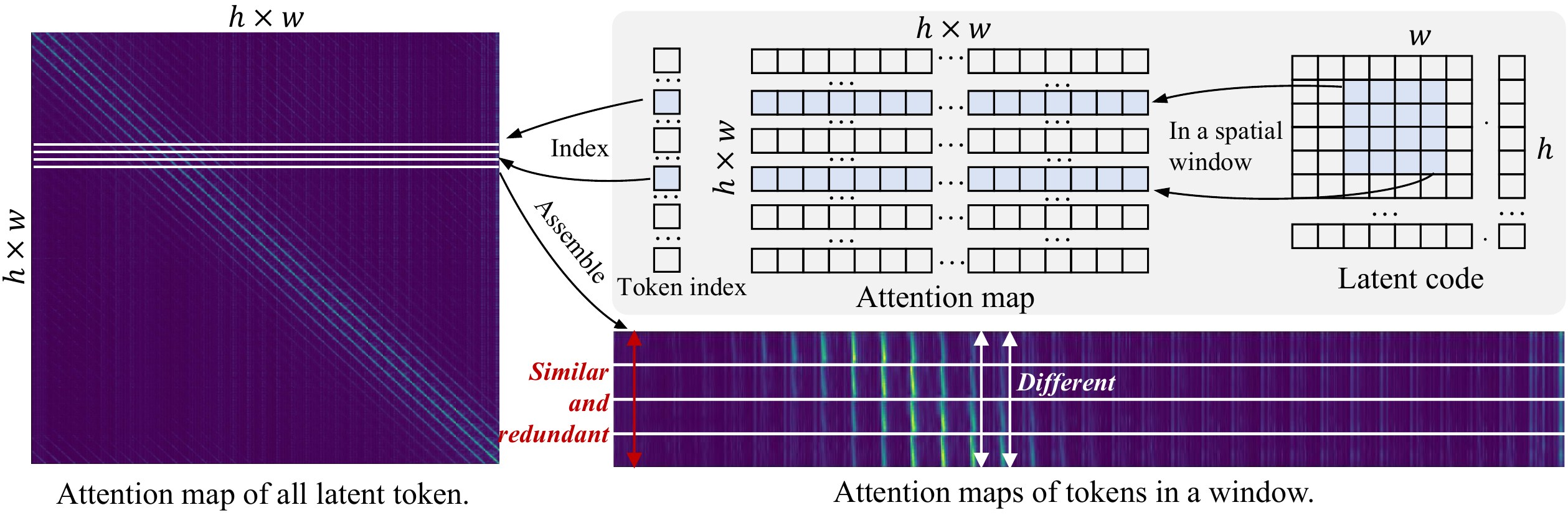
左图:$N\times N$ self-attention,$N=h\times w$(latent patch 网格展平后的 token 数)。格子 $(i,j)$ = token $i$ 对 token $j$ 的权重;对角线亮 = 看自己及空间近邻权重大。
右上:Latent Code 为 $w\times h$ 二维网格,浅蓝框 = 其中一个 $4\times4$ 空间窗;Token Index 为展平后的 1D 序列(省略号表示全长),浅蓝格 = 窗内 token 的 index(行优先时四行 index 段间常隔 $w$,不一定连续);Attention Map 每条横线 = 某 token 对全图 $N$ 个 target 的一行权重。
右下:每条横带 = 窗内 1 个 token 的 attention 行;图只画 4 条示意,论文实际 assemble 16 条($4\times4$)。单行内近处 target 亮、远处暗,属正常分布。
论文结论(竖着比行):固定横轴某一列(同一 target)——若 target 远离 该窗,16 行在该列几乎同色 → 重复计算 → GIIM 用窗口 mean proxy;若 target 靠近 窗,16 行明显不同 → 不能压成 1 个 proxy → TCM 用 window / shift-window 保留邻域差异。冗余指「行间对 distant target 几乎平行」,不是「远处暗就可删」。
3. Method
Latent $z \in \mathbb{R}^{C\times F\times H\times W}$ → patch embed → $z_s \in \mathbb{R}^{N\times D}$ + 3D PE → PT-Block (GIIM + TCM + text cross-attn + MLP).
GIIM (Eq. GIIM): reshape $z_s$ to $f\times h\times w$; per window $p_t\times p_h\times p_w$ average → proxy $P_a$; $\mathrm{SA}(P_a)$ then $\mathrm{CS}(z_s, \cdot)$; zero-init linear for stability.
$$z_s = \mathrm{CS}\big(z_s,\; \mathrm{SA}(\mathrm{Averaging}(z_s))\big)$$
3D VAE latent patch 化后进 PT-Block。
GIIM:窗口平均得 proxy → proxy 自注意力 → latent 作 Q、proxy 作 KV 的 cross-attention 广播全局信息。
全 SA:$2N^2D$。GIIM+TCM:$2\frac{N^2}{(p_fp_hp_w)^2}D + 2\frac{N^2}{p_fp_hp_w}D + \cdots$。2048² 时仅剩全 attention 的 2.3%(论文式 17)。
📄 Figure 3:PT-DiT 架构
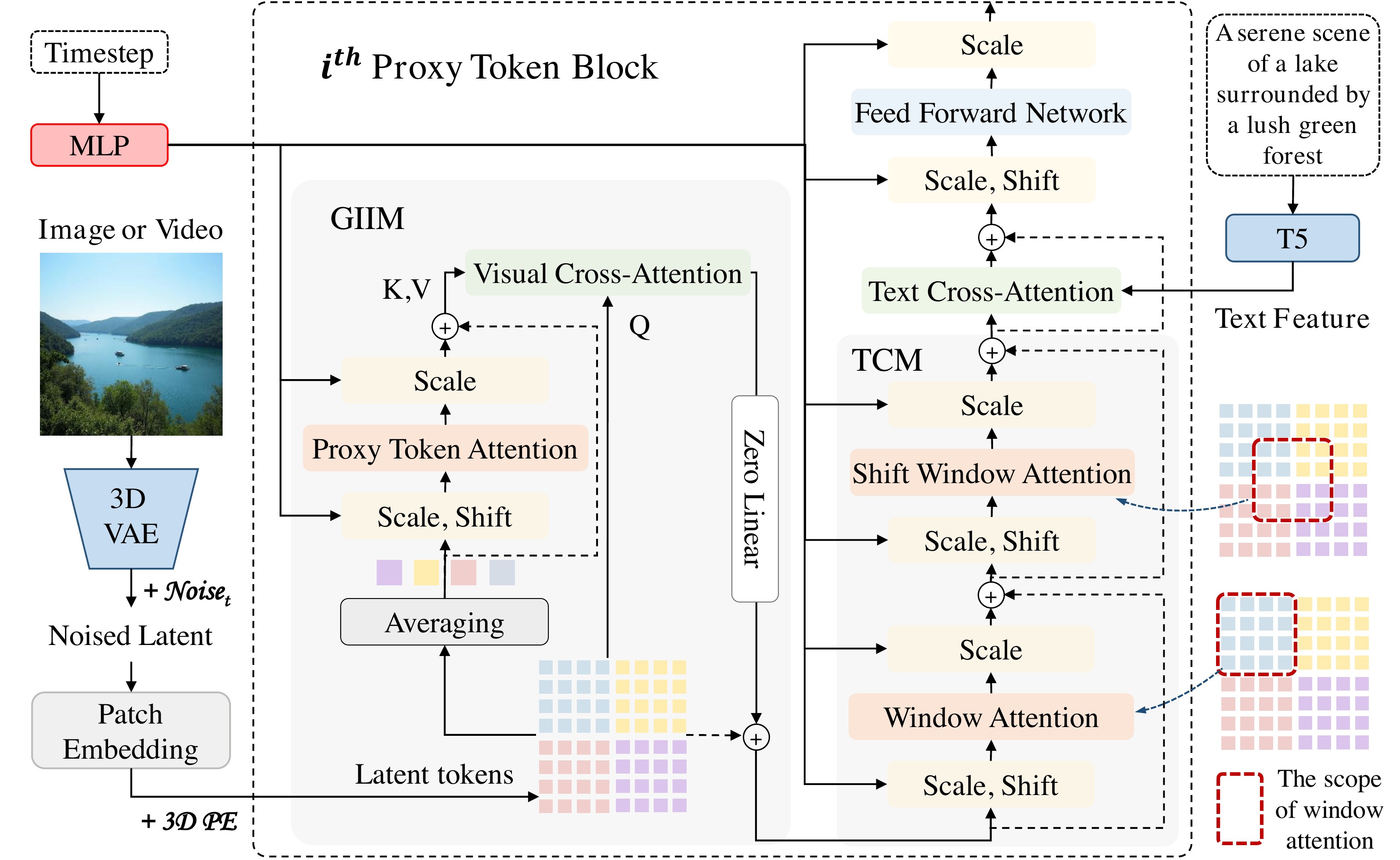
TCM (Eq. TCM): reshape to windows; $\hat{z_s}=\mathrm{WSA}(z_s)+z_s$; $z_w=\mathrm{SWSA}(\hat{z_s})+\hat{z_s}$ — Swin-style shift avoids grid artifacts (Fig. ablation_shift).
Compression ratios (image): $(p_f,p_h,p_w)$ = (1,2,2)/(1,4,4)/(1,8,8)/(1,16,16) at 256/512/1024/2048 — keep window count stable across resolutions for curriculum training.
Video: $p_f=4$ fixed; proxy compresses across time → efficient 3D spatiotemporal modeling.
TCM:窗口内 self-attention + 移位窗口,补 GIIM 稀疏全局丢掉的纹理细节。
分辨率越高压缩比越大,但窗口总数保持一致以利低→高分辨率训练。
视频固定时间维压缩 $p_f=4$。
w/o TCM:FID 19.30→69.07(ImageNet 256);w/o GIIM:23.71;w/o shift-window:23.59 + 明显 grid。Proxy 提取:Average 19.30 > Top-Left 20.84 > Random 21.00。
flowchart TB
subgraph PTBlock [PT-Block]
Z[Latent tokens z_s] --> GIIM
subgraph GIIM [GIIM]
Avg[Window average → proxy P_a] --> PSA[Proxy self-attention]
PSA --> CSA[Cross-attn: z_s Q, proxy KV]
end
CSA --> TCM
subgraph TCM [TCM]
WSA[Window self-attention] --> SWSA[Shift-window attention]
end
SWSA --> TXT[Text cross-attention + MLP]
end
💻 代码对照 — MindSpeed-MM PT-DiT
官方推理代码在昇腾 MindSpeed-MM/examples/qihoo_t2x(GitHub 360CVGroup/Qihoo-T2X 为 README/权重索引)。核心实现:mindspeed_mm/models/predictor/dits/pt_dit_diffusers.py 中 ProxyTokensTransformerBlock。
| 论文模块 | 代码 | 说明 |
|---|---|---|
| GIIM · Averaging | get_proxy_token(..., mode="mean") | 按 compress_ratios 窗口 reshape 后 mean → proxy |
| GIIM · Proxy SA | proxy_attn1 | proxy token 间 self-attention |
| GIIM · Cross broadcast | pvisual_attn2 + linear_1_visual (zero-init) | latent Q × proxy KV;zero_module 稳定训练 |
| TCM · Window SA | attn1 on window-grouped tokens | 每窗口内 self-attention |
| TCM · Shift-window | window_shift / window_Ishift | 3D cyclic shift,对应 SWSA |
| 压缩比 | compress_ratios, proxy_compress_ratios | 分辨率相关 $(p_f,p_h,p_w)$ |
| 推理入口 | inference_qihoo.py + qihoo_pipeline.py | examples/qihoo_t2x/inference_qihoo.sh |
① Proxy token 提取 — 对应 Eq. GIIM Averaging
消融表:mean(19.30) > top-left(20.84) > random(21.00) — 与论文 Table proxy 一致。
② PT-Block forward — GIIM → TCM 顺序
③ 推理配置
examples/qihoo_t2x/inference_model_image.json 指定权重路径;demo.txt 写 prompt;T5-XXL + Open-Sora-Plan VAE 1.2。权重:HuggingFace qihoo360/Qihoo-T2X。
4. Experiments
| Task | Metric | Qihoo | Best baseline |
|---|---|---|---|
| T2I | COCO FID-30k↓ | 15.70 | Imagen 7.27 |
| T2V | UCF FVD↓ | 384.03 | PixelDance 242.82 (U-Net) |
| T2V | MSR-VTT FVD↓ | 375.23 | DynamiCrafter 219.31 |
| T2V DiT | UCF FVD | 384 | CogVideoX 680 |
训练:PT-DiT/XL 1.1B;T2I 50M(32M LAION+18M HQ)三阶段 256→512→1024;T2V WebVid 10M + 3M HQ video。v-prediction, T5, cfg=6, 50 steps。
T2I FID 受数据分布影响非 SOTA,但质量定性可比 Flux/PixArt。T2V 在 DiT 系 UCF/MSR-VTT FVD 领先 CogVideoX/EasyAnimateV4。
64GB Ascend 910B 可训 PT-DiT/XL:图 2048² 或视频 512²×288 帧。
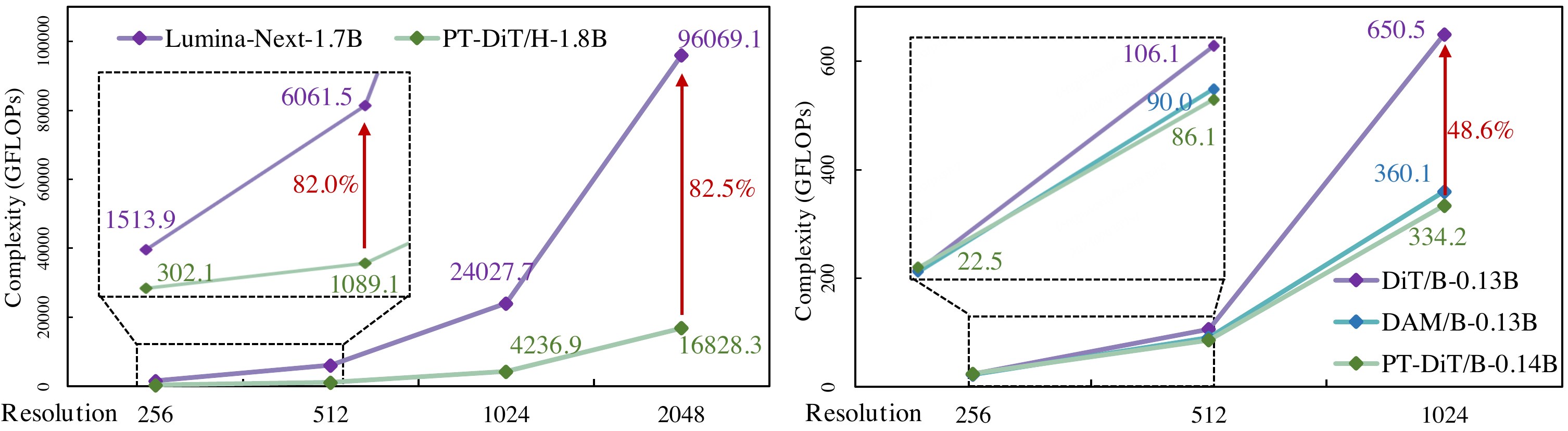
PT-DiT/H vs Lumina-Next:512/2048 上 GFLOPs −82%。PT-DiT/XL T2V 算力仅为 CogVideoX/EasyAnimate 的 50%;训练显存随帧数近线性,EasyAnimate 全 3D attention 陡增。
📄 Figure 5–7:T2I / T2V / T2MV 定性



📄 Figure 8–10:算力对比 & Shift-window 消融

5. Conclusion
PT-DiT uses proxy-tokenized attention + window/shift-window for efficient DiT on T2I/T2V/T2MV. Competitive quality, major FLOPs/memory savings — especially for long video sequences.
用 proxy 稀疏全局 + 局部 window 补细节;一套架构覆盖文生图/视频/多视角;为长高分辨率 DiT 提供可扩展路径。
COCO FID 非顶尖;推理依赖昇腾 MindSpeed 栈;T2MV 仅 40k Objaverse 子集;与 FlashAttention/稀疏 kernel 未联合报告。
符号速查表
| 符号 | 含义 |
|---|---|
| PT-DiT | Proxy-Tokenized Diffusion Transformer |
| GIIM | Global Information Interaction Module(proxy SA + cross) |
| TCM | Texture Complement Module(WSA + SWSA) |
| $P_a$ | 窗口平均得到的 proxy token 集合 |
| $(p_f,p_h,p_w)$ | 时间/高/宽压缩比 |
| Qihoo-T2I/V/MV | 文生图 / 文生视频 / 文生多视角产品 |
论证总览
↓
GIIM:窗口平均 proxy → SA(proxy) → CS(latent, proxy)
↓
TCM:window + shift-window 补局部纹理(防 grid)
↓
分辨率自适应压缩比 + 视频 p_f=4 → 同一骨架 T2I/T2V/T2MV
↓
算力:≈51% DiT / 66% PixArt;T2V FVD DiT 系 SOTA;显存随帧数缓增
🧩 结构化十问(AI 解构)
Q1 · 解决什么问题?
Q2 · PT-DiT 核心机制?
Q3 · 与 DAM / AgentAttention 区别?
Q4 · 为什么用平均而不是取左上角 token?
Q5 · 压缩比怎么设?
Q6 · TCM 为什么必要?
Q7 · Qihoo-T2X 包含哪些任务?
Q8 · 实验效果?
Q9 · 代码在哪?
MindSpeed-MM/examples/qihoo_t2x;模型 pt_dit_diffusers.py;权重 HuggingFace qihoo360/Qihoo-T2X。GitHub 360CVGroup/Qihoo-T2X 主要为文档入口。Q10 · 与 CogVideoX / FancyVideo 关系?
🔬 深挖
「远处冗余、近处关键」的设计含义
GIIM 负责低频全局布局(谁在哪、整体色调);TCM 负责高频邻域关系(边缘、纹理)。这与多尺度信号处理直觉一致,也解释为何不能只砍 attention 而不加 window。
T2MV = 静态物体「假视频」
把环绕物体的多视角当作 $F=24$ 视频,复用 PT-DiT 时空压缩——同一套 proxy 机制在「帧间冗余极大」时收益最高。
批判性思维
- FID 基准:MS-COCO 零样本对自有 50M 混合数据不友好,需更多 in-domain 指标。
- 与 kernel 融合:proxy 减的是有效 $N$,FlashAttention 减的是常数;二者是否可叠加未测。
- 平均池化信息损失:极高压缩比 (1,16,16) 下单 proxy 能否代表复杂语义?Table ratio 在 (1,4,4) 已开始退化。
- 生态:主力代码在 Gitee+Ascend,PyTorch/CUDA 社区复现门槛高于 CogVideoX。