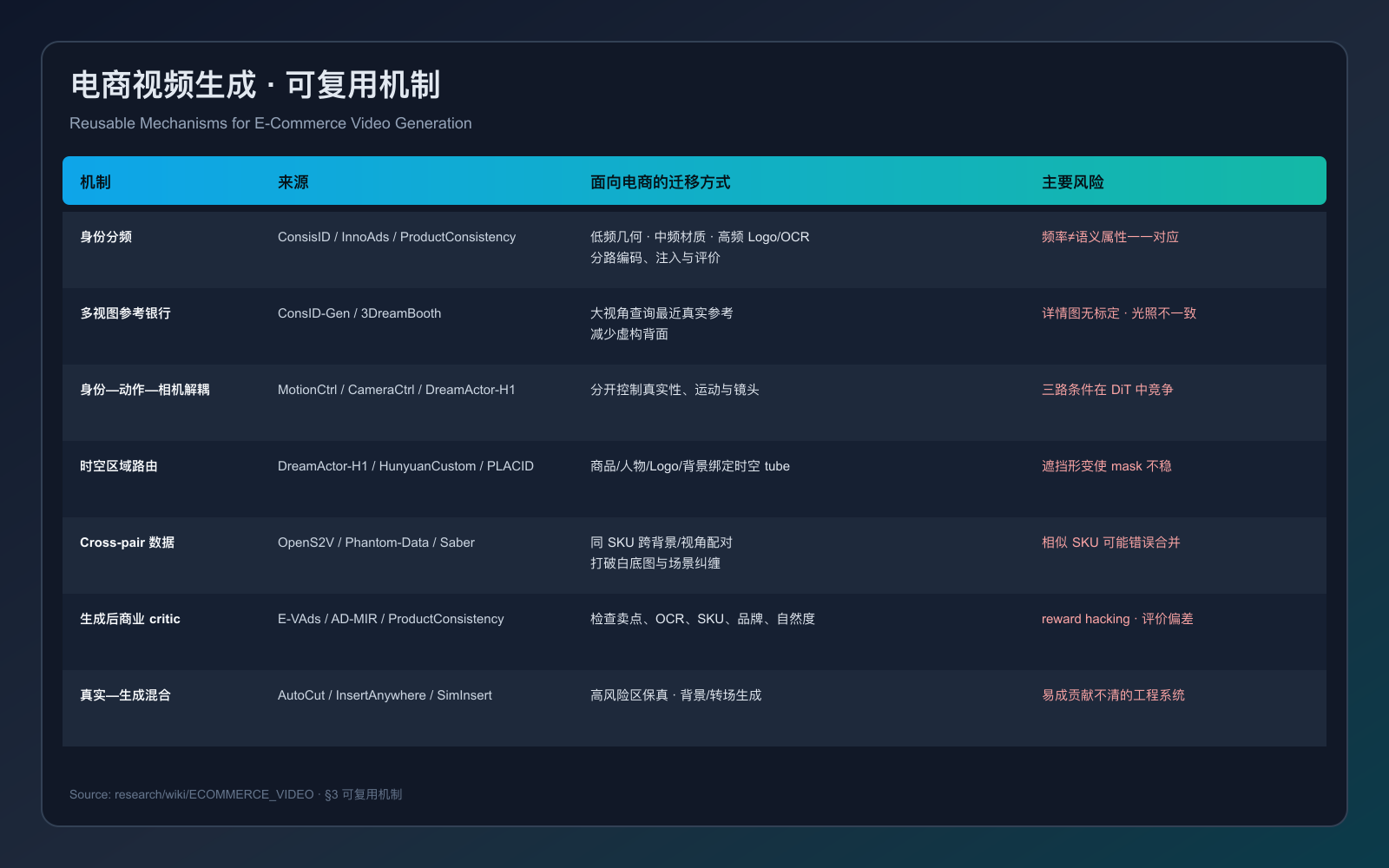
MoFu — Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
任务:多主体视频生成——给定文本 + 多张参考图,生成多主体一致、尺度自然的视频。
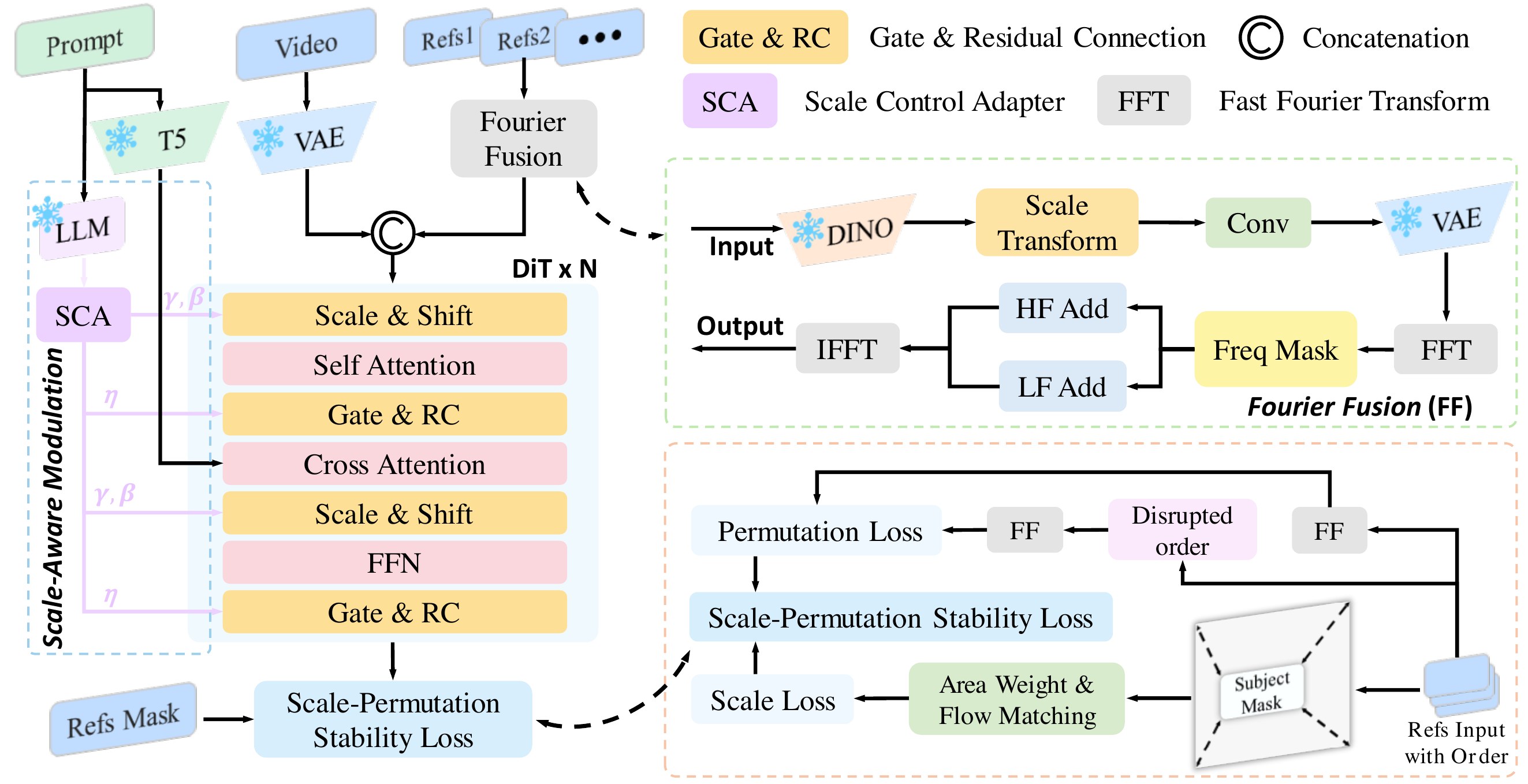
Lay2Story — Extending Diffusion Transformers for Layout-Togglable Story Generation
Storytelling:用一组 prompt 生成多帧图,主角外观要一致。现有 training-free(改 cross-frame attention)和 training-based 都难精细控制位置、衣着、表情、姿势,且缺大规模带 layout 标注的数据。
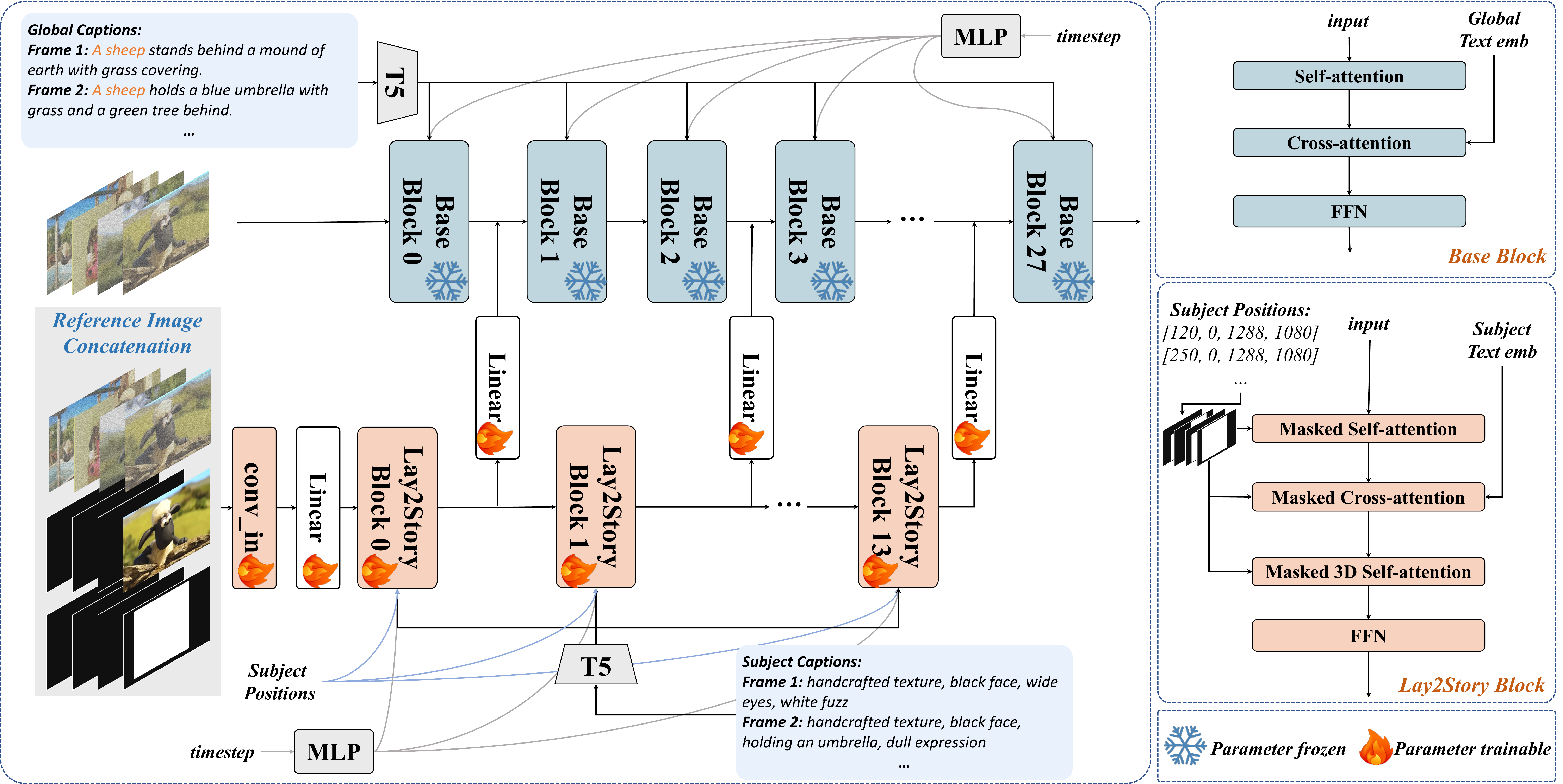
WISA — World Simulator Assistant for Physics-Aware Text-to-Video Generation
Sora、Kling、CogVideoX 能生成逼真视频,但常违反物理:橡皮擦越擦字越黑、苹果落水没有溅起水花、液体运动像随机噪声。根因是抽象物理定律与像素生成之间缺桥梁——模型只学「画面像什么」,没学「过程该怎么演化」。
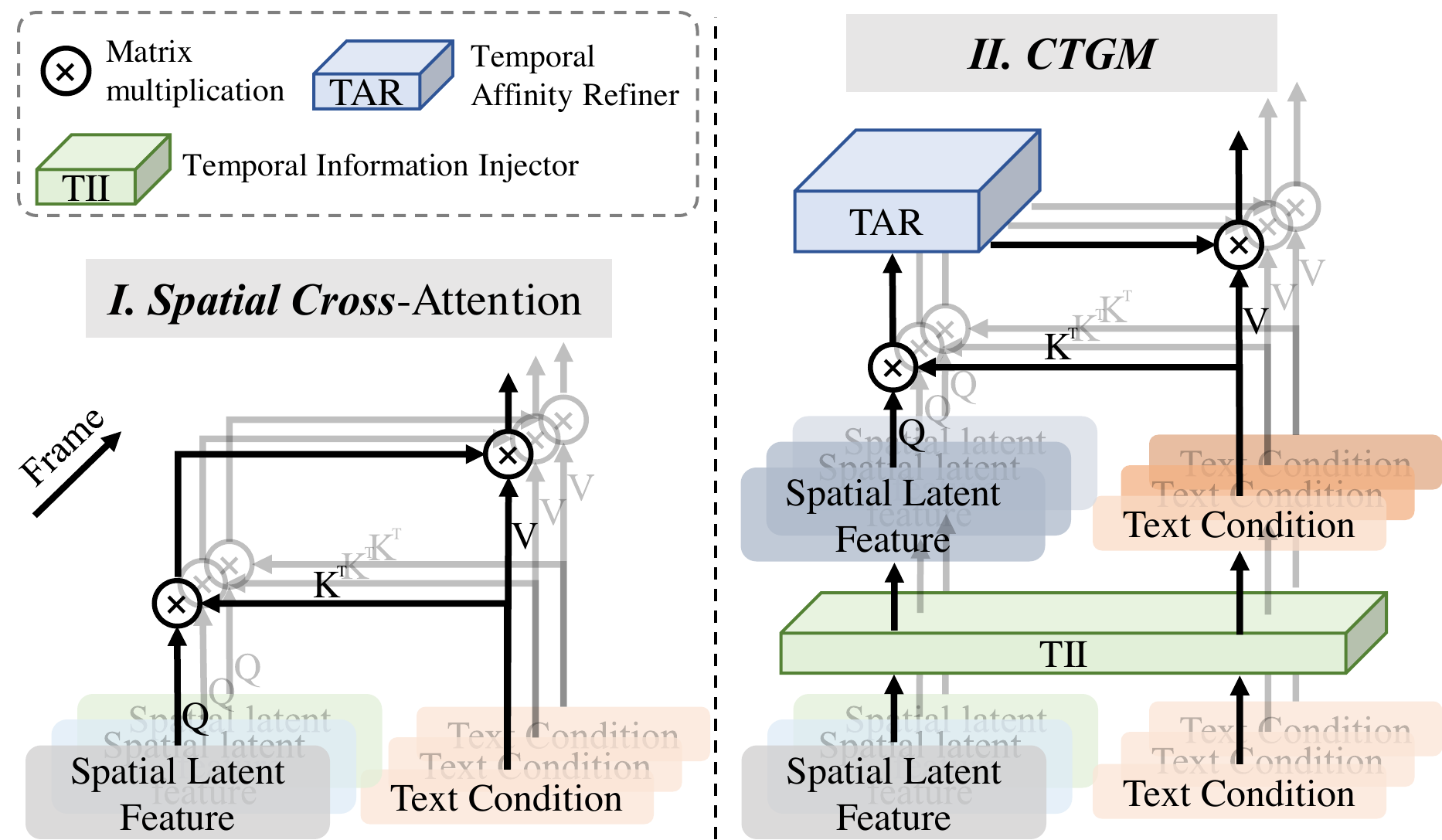
FancyVideo — Towards Dynamic and Consistent Video Generation via Cross-frame Textual Guidance
痛点:AnimateDiff 等 T2V 把同一段 text embedding 复制到每一帧做 spatial cross-attention → [verb] 关注区几乎不变 → 动作弱、长视频更明显。
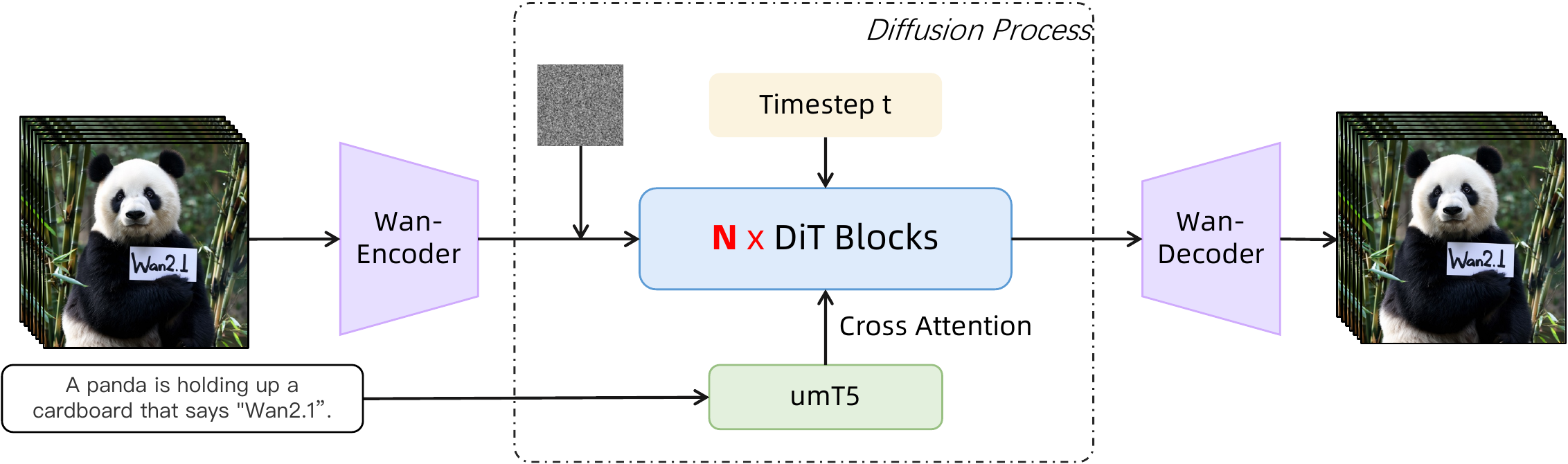
Wan — Open and Advanced Large-Scale Video Generative Models (Wan2.1)
开源文生视频(HunyuanVideo、CogVideoX、Mochi)与闭源 Sora 仍有性能/能力/效率差距。Wan2.1 = 阿里 Wan 团队全栈技术报告 + 开源:Wan-VAE(3D 因果、4×8×8 压缩、127M 参数 + feature cache 流式编解码)+ DiT + Flow Matching(umT5 文本、3D RoPE 全时空注意力、共享 timestep MLP 省 25% 参)+ 十亿级图文视频预训练(256→480→720 分辨率课程)+ Wan-Bench 自动评测。提供 1.3B(8.19GB VRAM 消费级)与 14B 两档;覆盖 T2V/I2…
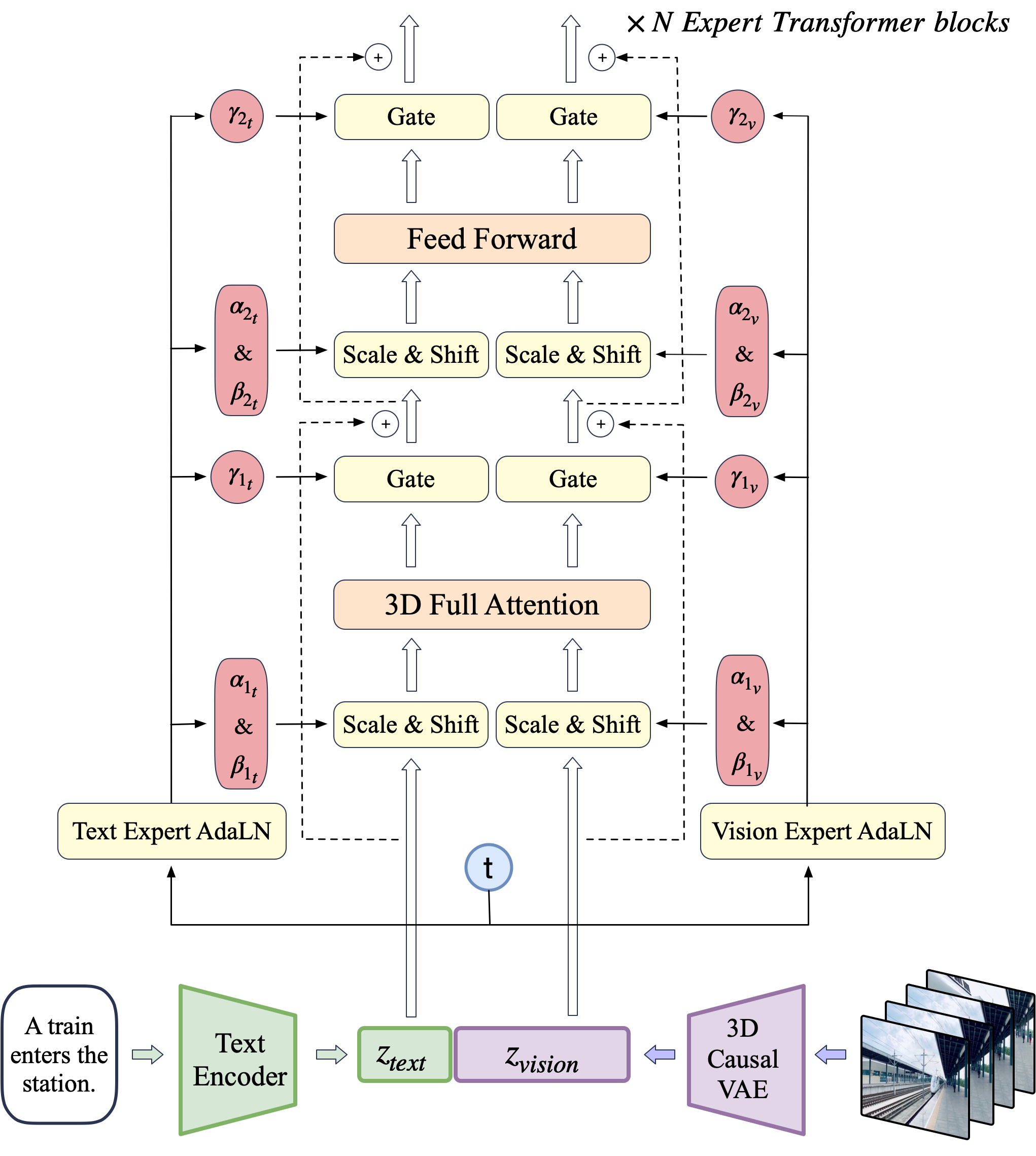
CogVideoX — Text-to-Video Diffusion Models with An Expert Transformer
文生视频 = 扩散 + DiT,但旧模型动作小、时长短、叙事难连贯。CogVideoX 四件套:3D 因果 VAE(时空 8×8×4 压缩,减 flicker)+ Expert Transformer(文本/视频 Expert AdaLN + 3D full attention 替代 2D+1D 分离注意力)+ Multi-Resolution Frame Pack(混时长/分辨率 batch 训练)+ 密集 caption 流水线(Panda70M → CogVLM 帧 caption → GPT-4 汇总 → CogVLM2-Caption)。产出 768×1360、16fps、10 秒视…
Recent
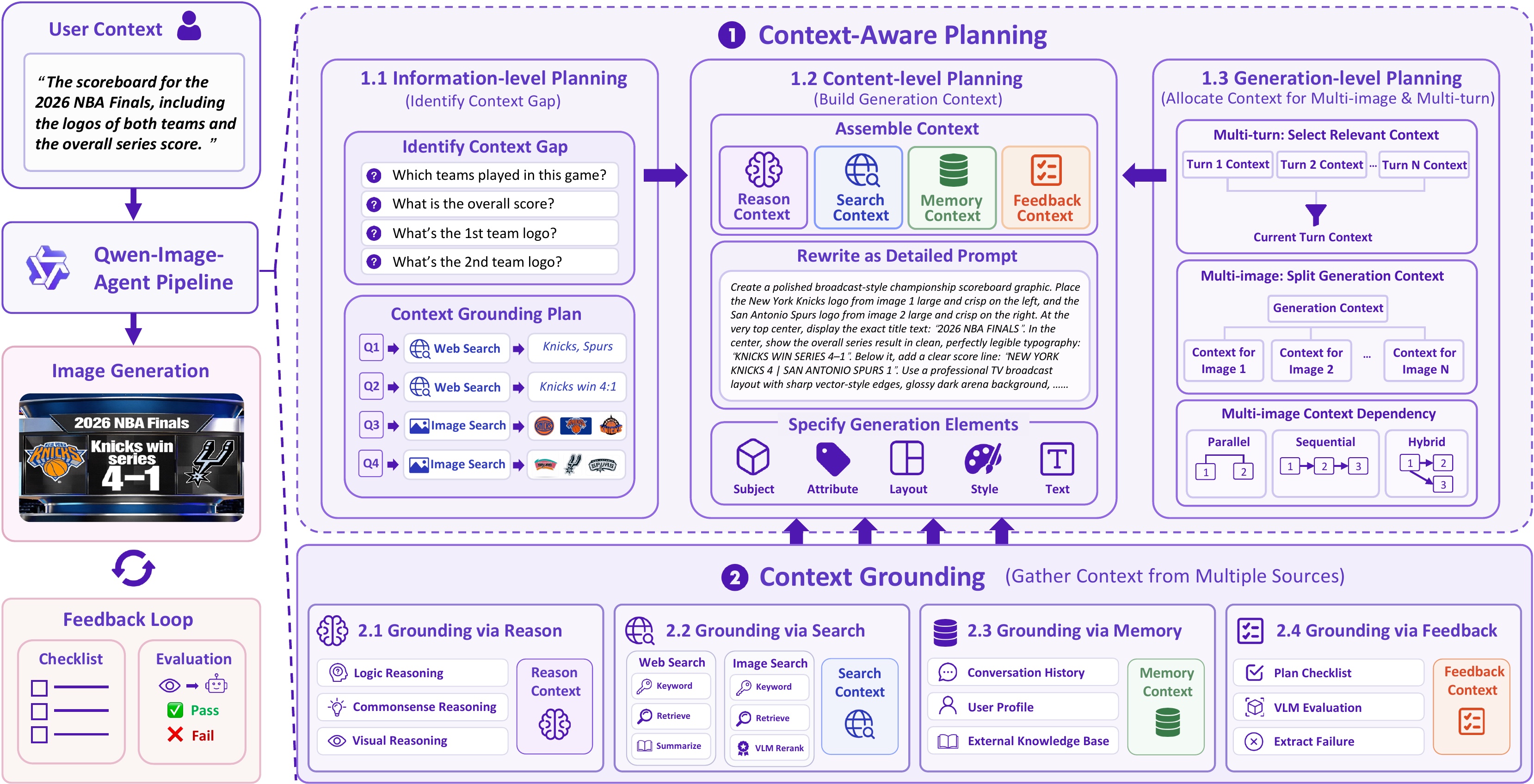
Recent