
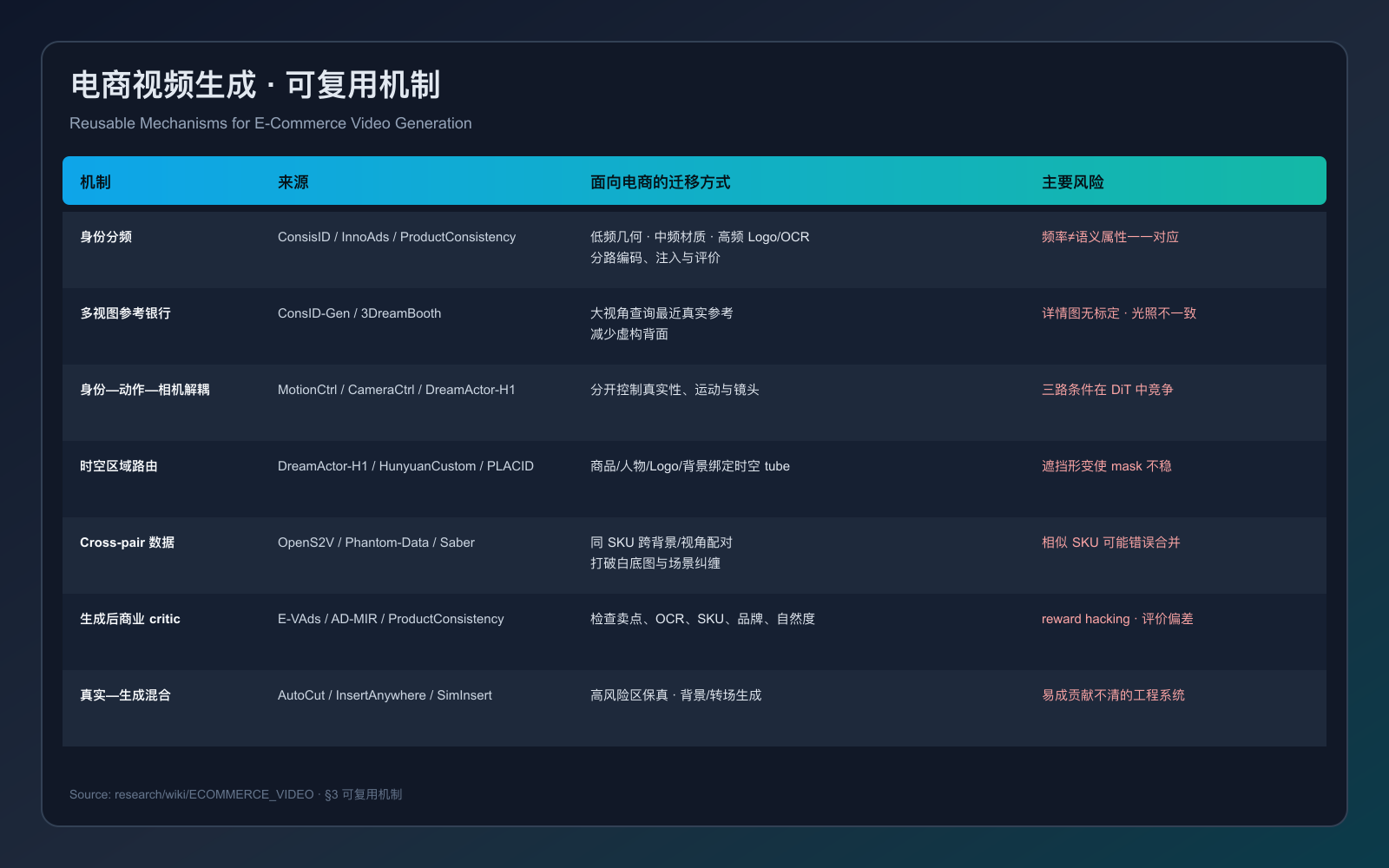
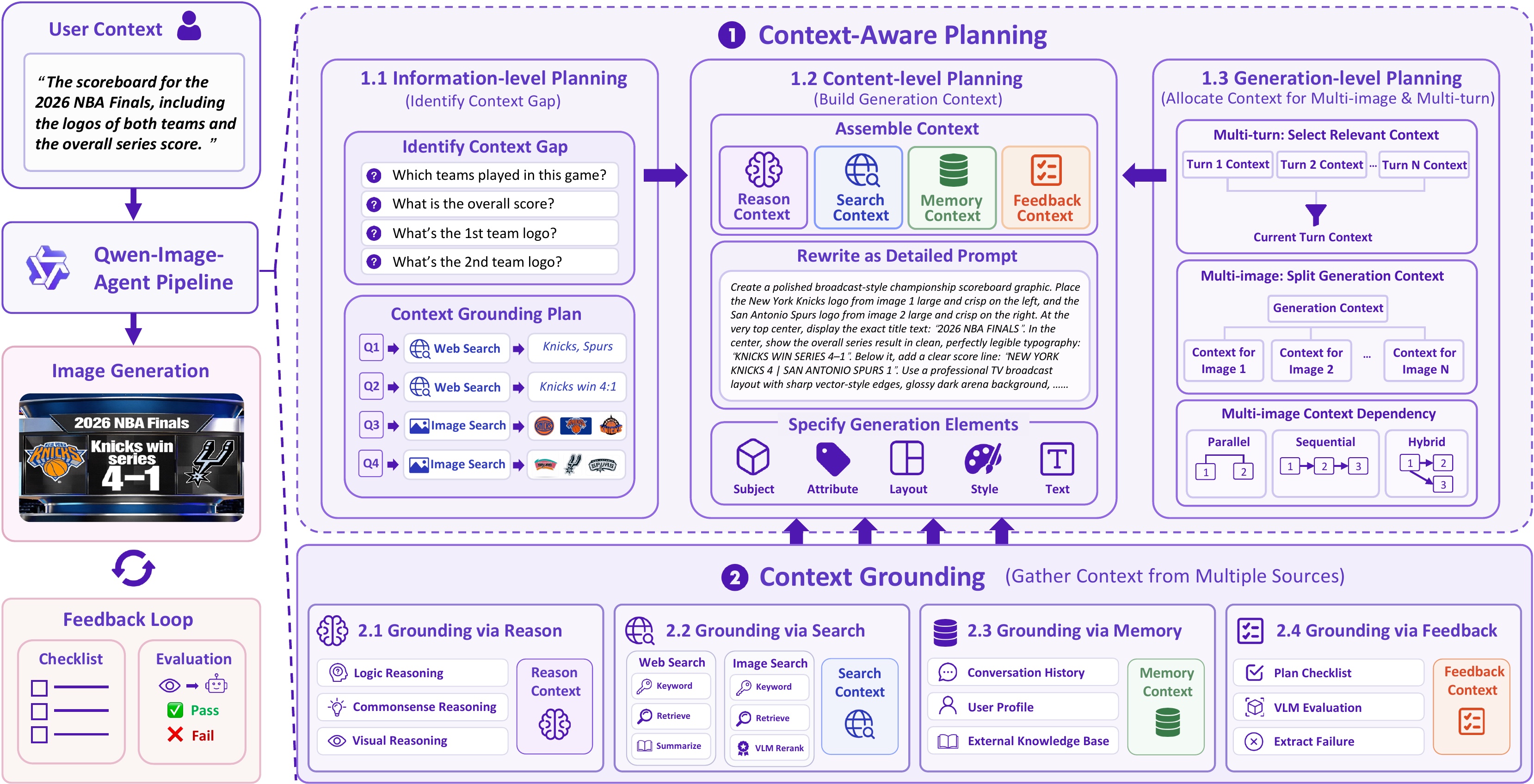
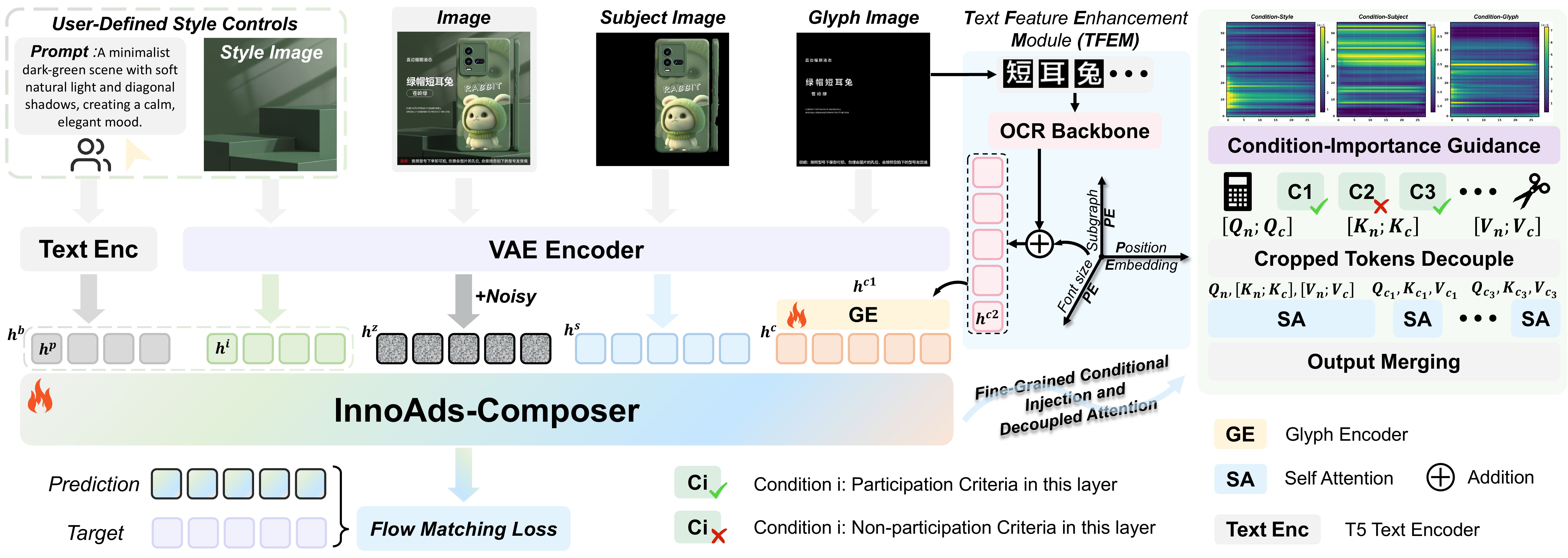
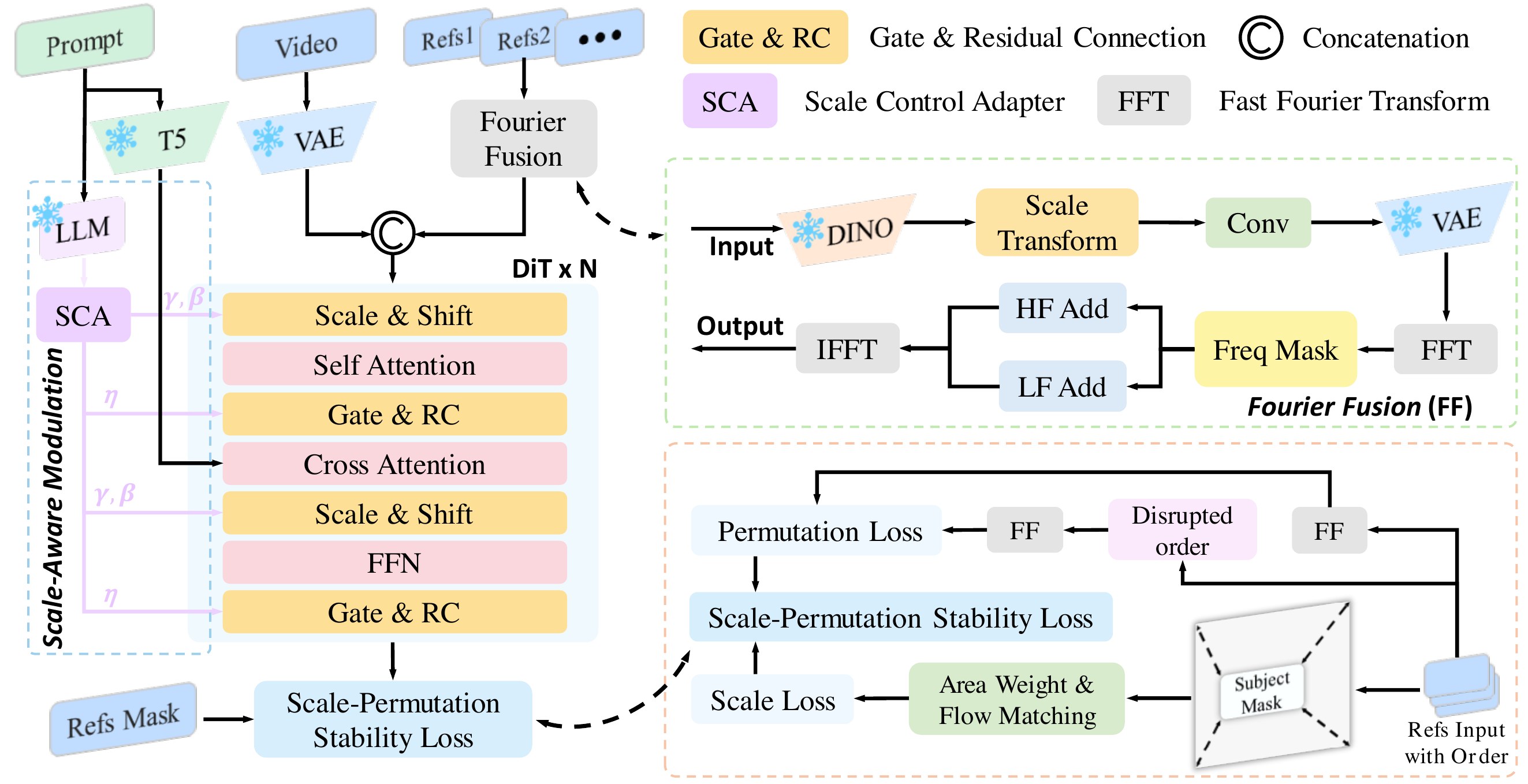
There are the overall of paper with code for CV / AIGC / LLM / VLM.
https://github.com/Gojay001/paper-with-code-skills.
[Updating…]
There are the overall of paper with code for CV / AIGC / LLM / VLM.
https://github.com/Gojay001/paper-with-code-skills.
[Updating…]
Update your browser to view this website correctly. Update my browser now