本文整理 BatchNorm / LayerNorm / RMSNorm 的作用与差异,并给出与 PyTorch 思路一致的简化实现(dummy),便于对照官方源码阅读。
Contents
概述与对比
归一化的作用
- 稳定输入分布(常见目标为零均值、单位方差),减轻内部协变量偏移带来的影响;
- 使各层学习目标相对稳定,梯度更平滑(减轻激活函数饱和区带来的梯度问题);
- 梯度更稳定后,往往可以使用更大学习率,从而加快收敛。
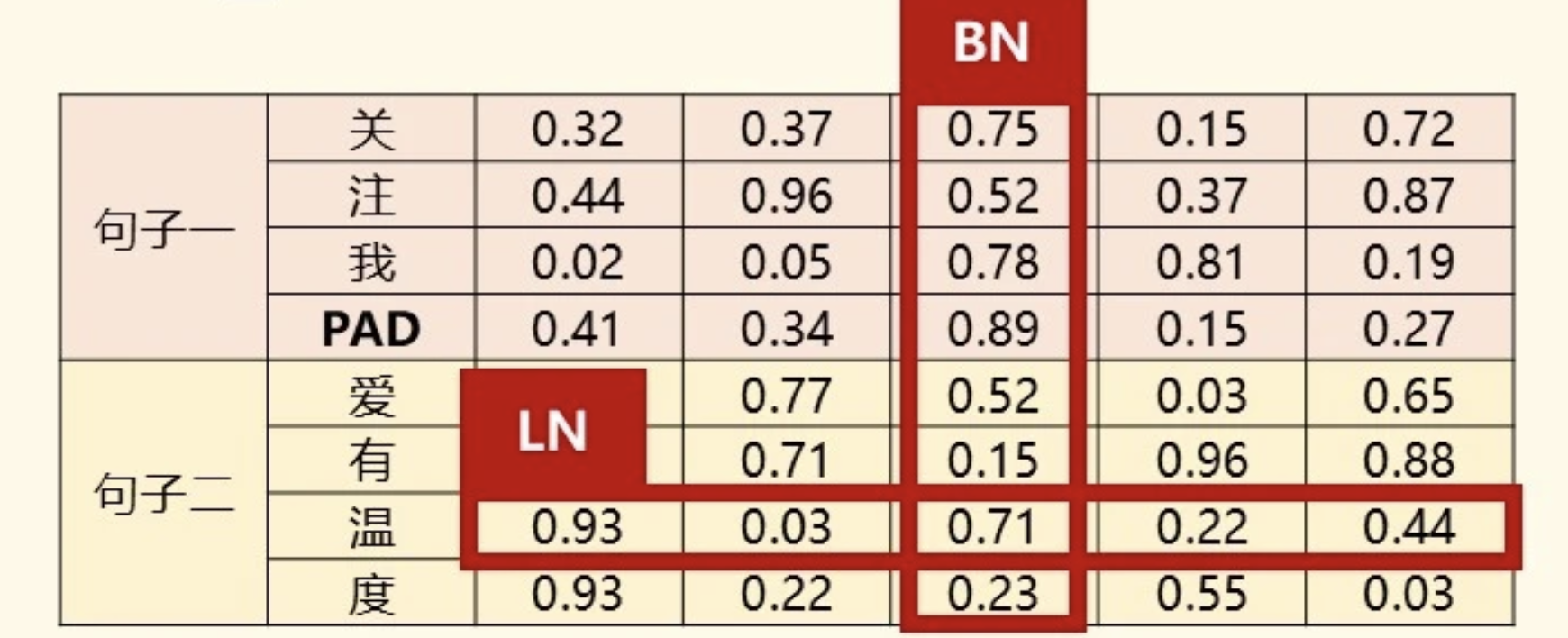
BN 与 LN 的对比
BN:逐通道归一化,在 NHW(或序列场景下的 NL)上统计;LN:逐样本 / 逐 token 归一化;图像上常对 CHW,序列上对最后一维 D。
CNN:图像具有空间不变性,同一通道在不同空间位置的可比性强,适合跨样本、逐通道做 BN。
Transformer:LN 在每个样本的每个 token 内,对特征维 D 独立归一化,使每个 token 的特征向量分布稳定。
统一形式:先标准化,再用可学习参数做仿射变换:y = scale * x + shift(RMSNorm 常省略 bias)。
极简伪代码
import torch |
BatchNorm
- 图像 NCHW:在 NHW 上统计,逐通道归一化(
normalized_shape=[N,H,W]); - 序列 NCL:在 NL 上统计,同样是逐通道(
normalized_shape=[N,L])。
PyTorch 官方实现入口:
文档中的形状约定(节选):
class BatchNorm1d(_BatchNorm): |
更完整的 BatchNorm2d dummy(支持 affine、track_running_stats、多维度输入扩展思路;类名避免与上文极简版冲突):
import torch |
LayerNorm
- 图像 NCHW:可按样本在 CHW 上归一化(
normalized_shape=[C,H,W]); - 序列 NLD:通常只在最后一维 D 上归一化(
normalized_shape=[D])。
nn.LayerNorm 负责管理可学习的 weight / bias,核心计算多委托给 torch.nn.functional.layer_norm。
官方入口:
文档示例(节选):
class LayerNorm(Module): |
functional 形式的 dummy(对应「在 normalized_shape 指定的一组末尾维度上」求均值方差):
def layer_norm(input, normalized_shape, weight=None, bias=None, eps=1e-5): |
底层实现还可对照 CPU / CUDA kernel(阅读源码时便于理解边界与数值稳定性):
RMSNorm
相比 LN:去掉减均值(中心化),只保留除以 RMS 的缩放;仿射部分往往只有缩放 gamma,无 bias。
直观理解:中心化与偏置可由后续 FFN 等层补偿;缩放对稳定梯度幅度往往更关键。形式上若存在线性层:y = W(x - μ) + b = Wx + (b - Wμ),偏置与中心化存在冗余空间。
官方接口:
class RMSNorm(Module): |