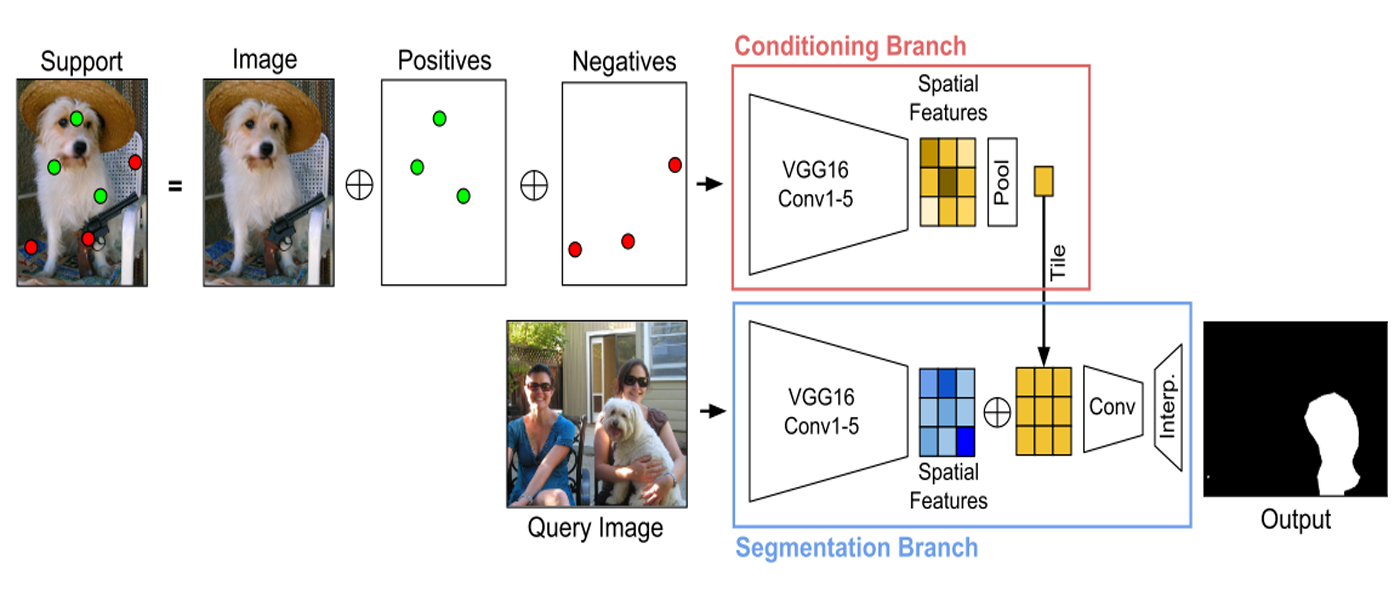

co-FCN(Conditional Networks for Few-Shot Semantic Segmentation)[1] handle sparse pixel-wise annotations to achieve nearly the same accuracy. There are some details of reading and implementing it.
Update your browser to view this website correctly. Update my browser now

