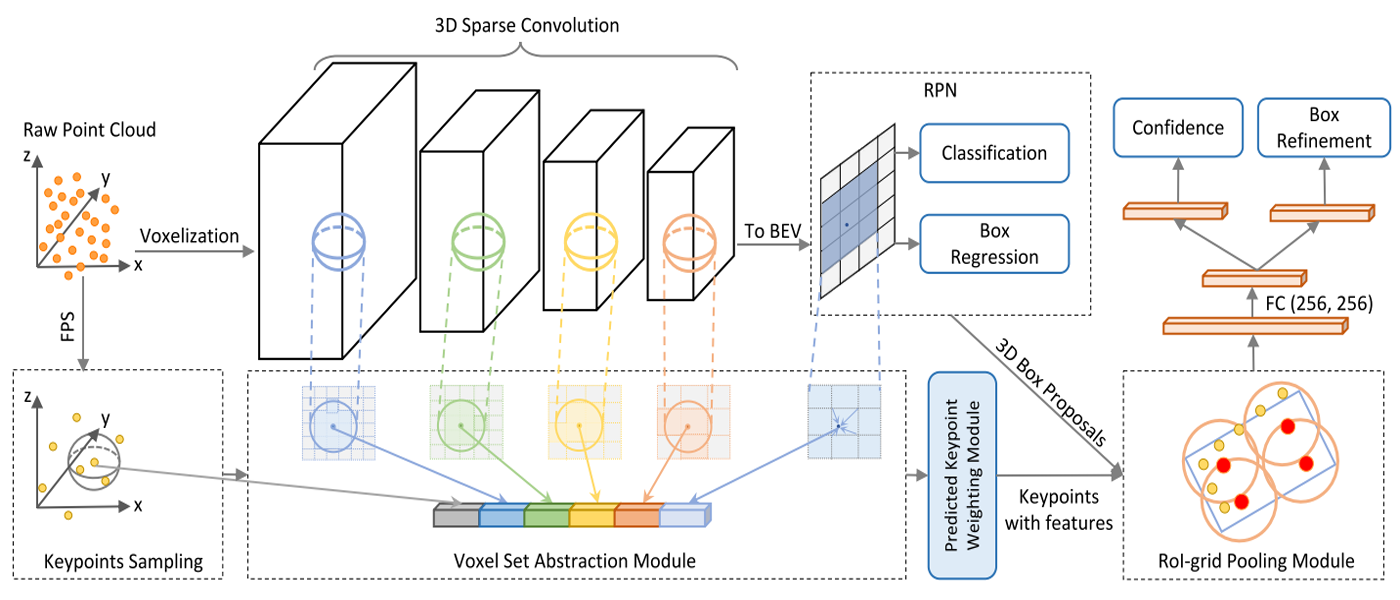

PV-RCNN[1] is a 3D Object Detection framework to integrate
3D voxel CNNandPointNet-based set abstractionto learn more discriminative point cloud features. The most contributions in this papar is two-stage strategy including thevoxel-to-keypoint3D scene encoding and thekeypoint-to-gridRoI feature abstraction. There are some details of reading and implementing it.

