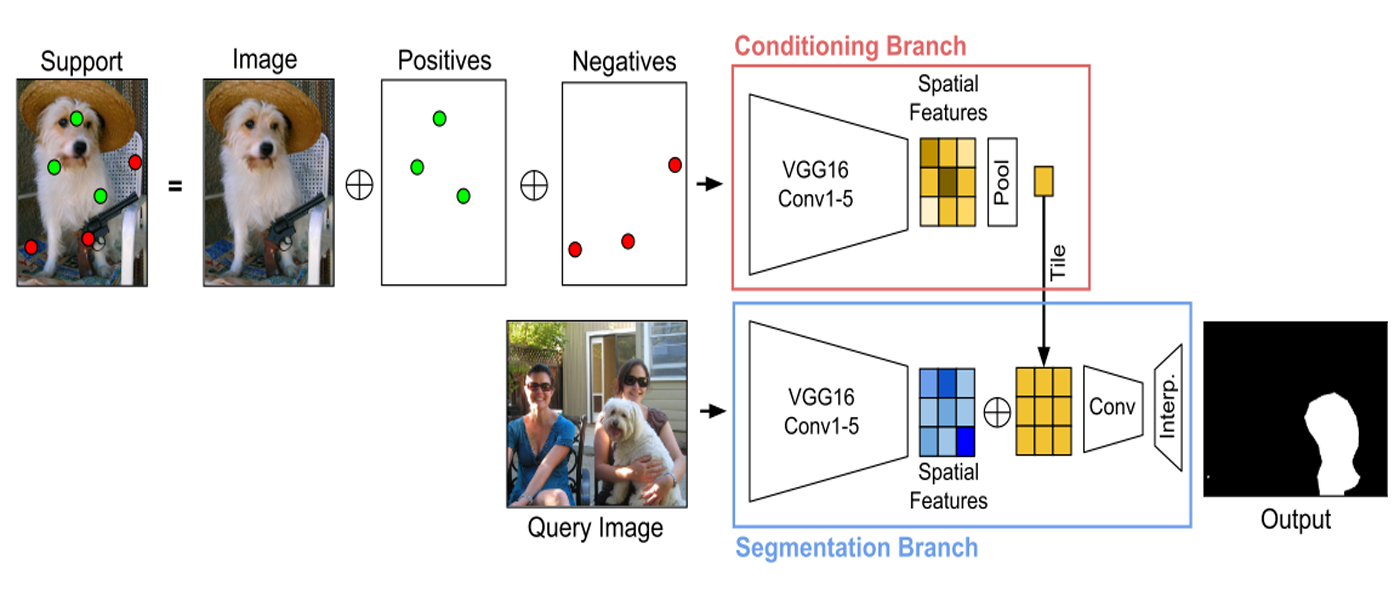
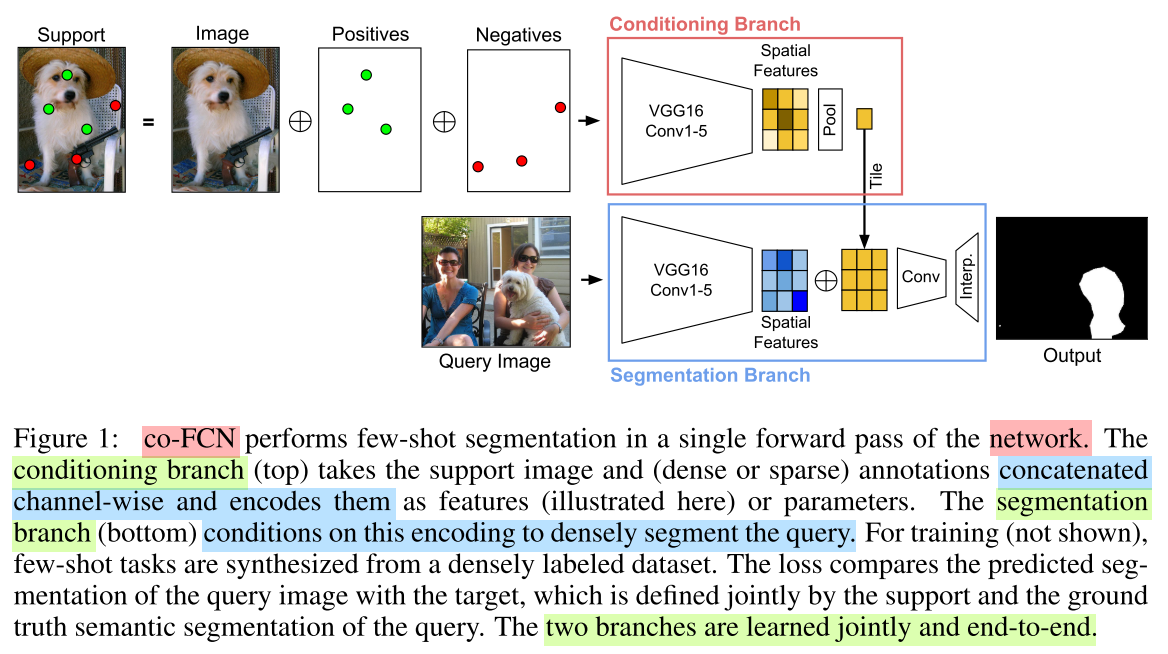
co-FCN(Conditional Networks for Few-Shot Semantic Segmentation)[1] handle sparse pixel-wise annotations to achieve nearly the same accuracy. There are some details of reading and implementing it.
Contents
Paper & Code & note
Paper: Conditional Networks for Few-Shot Semantic Segmentation(ICLR 2018 paper)
Code: [Code]
Note: Mendeley
Paper
Abstract

- They propose the co-FCN, a conditional network learned by end-to-end optimization to perform fast, accurate few-shot segmentation.
- The network conditions on an annotated support set of images via
feature fusionto do inference on an unannotated query image.- Annotations are instead conditioned on in a
single forward pass, making our method suitable for interactive use.
Problem Description
Some current methods rely on meta-learning, or learning to learn, in order to quickly adapt to new domains or tasks.
- It cannot be applied out-of-the-box to the structured output setting due to the
high dimensionality of the output space. - The statistical dependencies among outputs that result from the
spatial correlation of pixels in the input.
Problem Solution
- Our contributions cover handling sparse pixel-wise annotations, conditioning features vs. parameters.
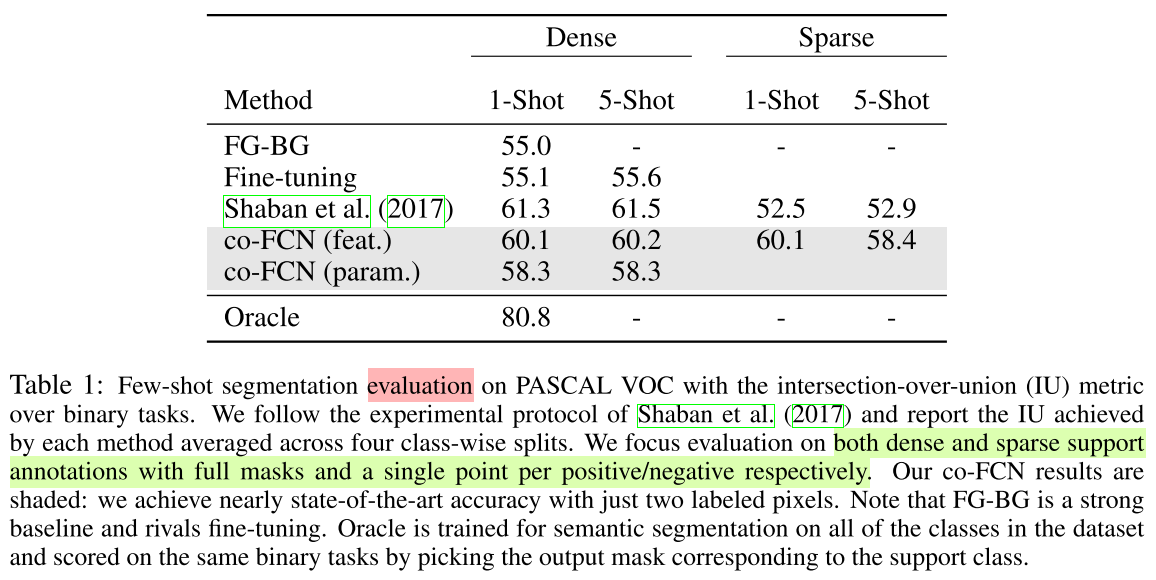
- Our method achieves
nearly the same accuracywith only one positive and one negative pixel.
Conceptual Understanding
Experiments
Code
[Updating]
Note
[Updating]
References
[1] Rakelly K, Shelhamer E, Darrell T, et al. Conditional networks for few-shot semantic segmentation[J]. 2018.