OSLSM(One-Shot Learning for Semantic Segmentation)[1] firstly proposed two-branch approach to one-shot semantic segmentation. Conditioning branch trains a network
to get parameter$\theta$, and Segmentaion branchoutputs the final maskbased on parameter $\theta$. There are some details of reading and implementing it.
Contents
Paper & Code & note
Paper: One-Shot Learning for Semantic Segmentation(BMVC 2017 paper)
Code: Caffe
Note: Mendeley
Paper
Abstract

- They extend
low-shot methodsto supportsemantic segmentation.- They train a network that
produces parametersfor a FCN.- They use this FCN to perform dense
pixel-level predictionon a test image for thenew semantic class.- It outperforms the state-of-the-art method on the
PASCAL VOC 2012dataset.
Problem Description
A simple approach to performing one-shot semantic image segmentation is to fine-tune a pre-trained segmentation network on the labeled image.
- This approach
is prone to over-fittingdue to the millions of parameters being updated. - The fine tuning approach to one-shot learning, which
may require many iterations of SGDto learn parameters for the segmentation network. - Besides, thousands of dense features are computed from a single image and one-shot methods
do not scale well to this many features.
Problem Solution
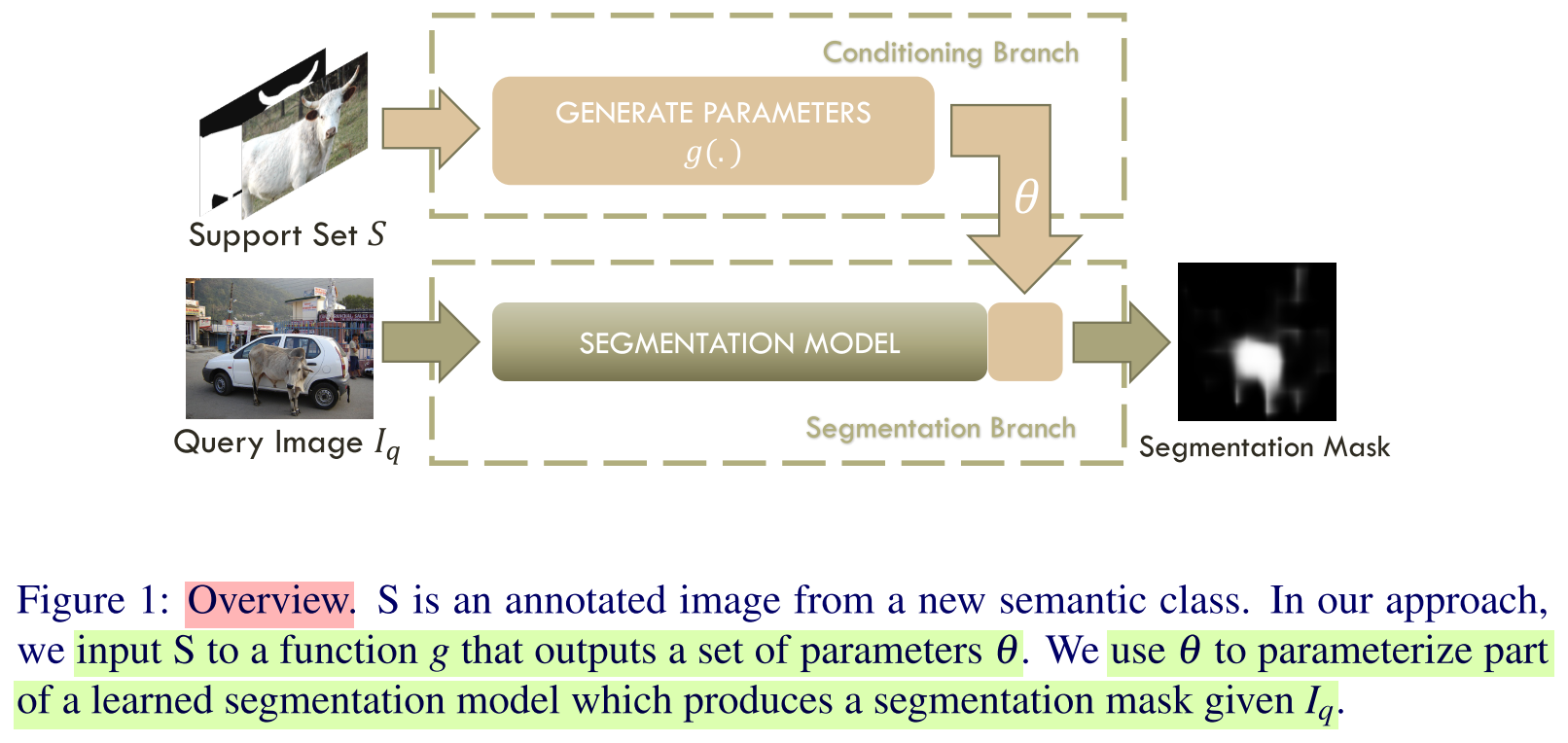

Conceptual Understanding
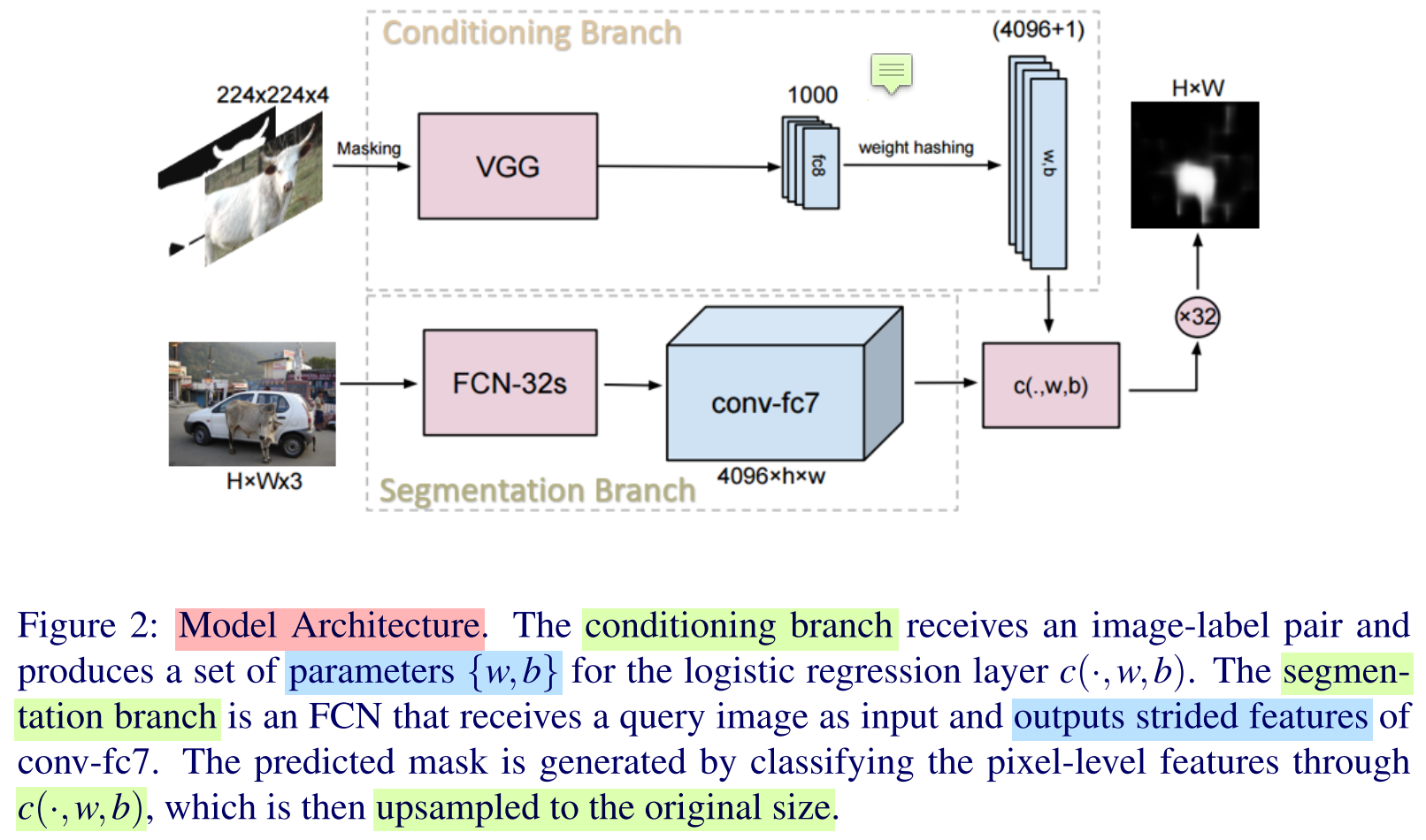
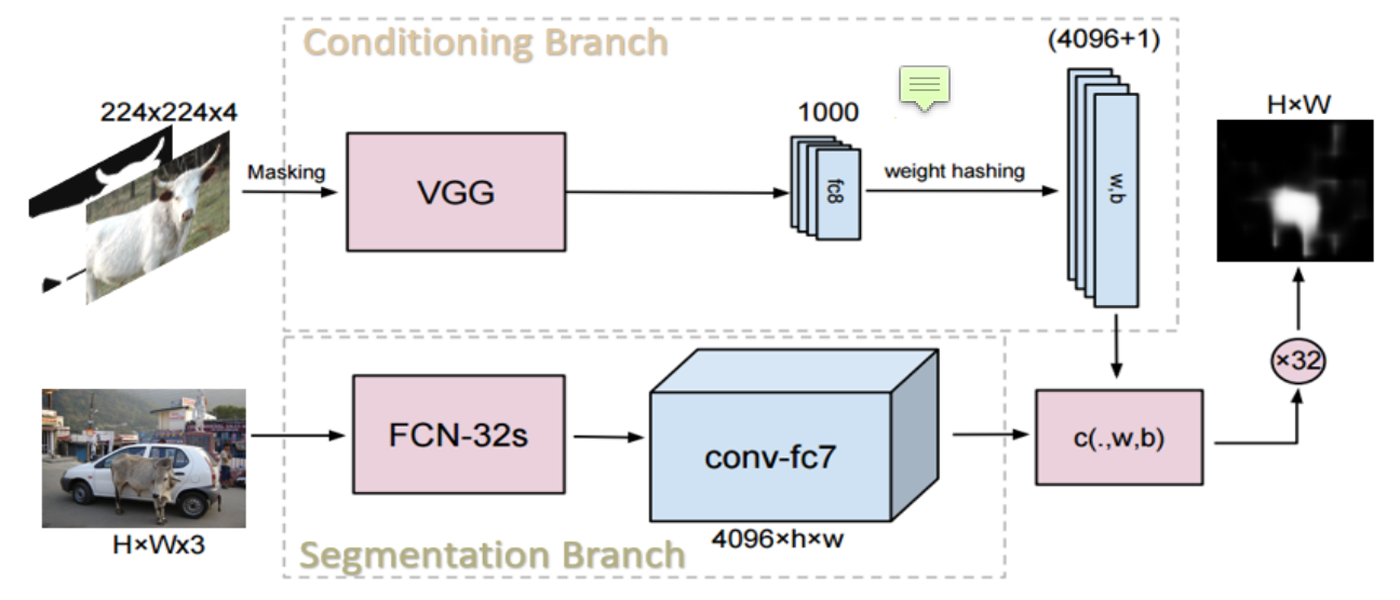
Core Conception
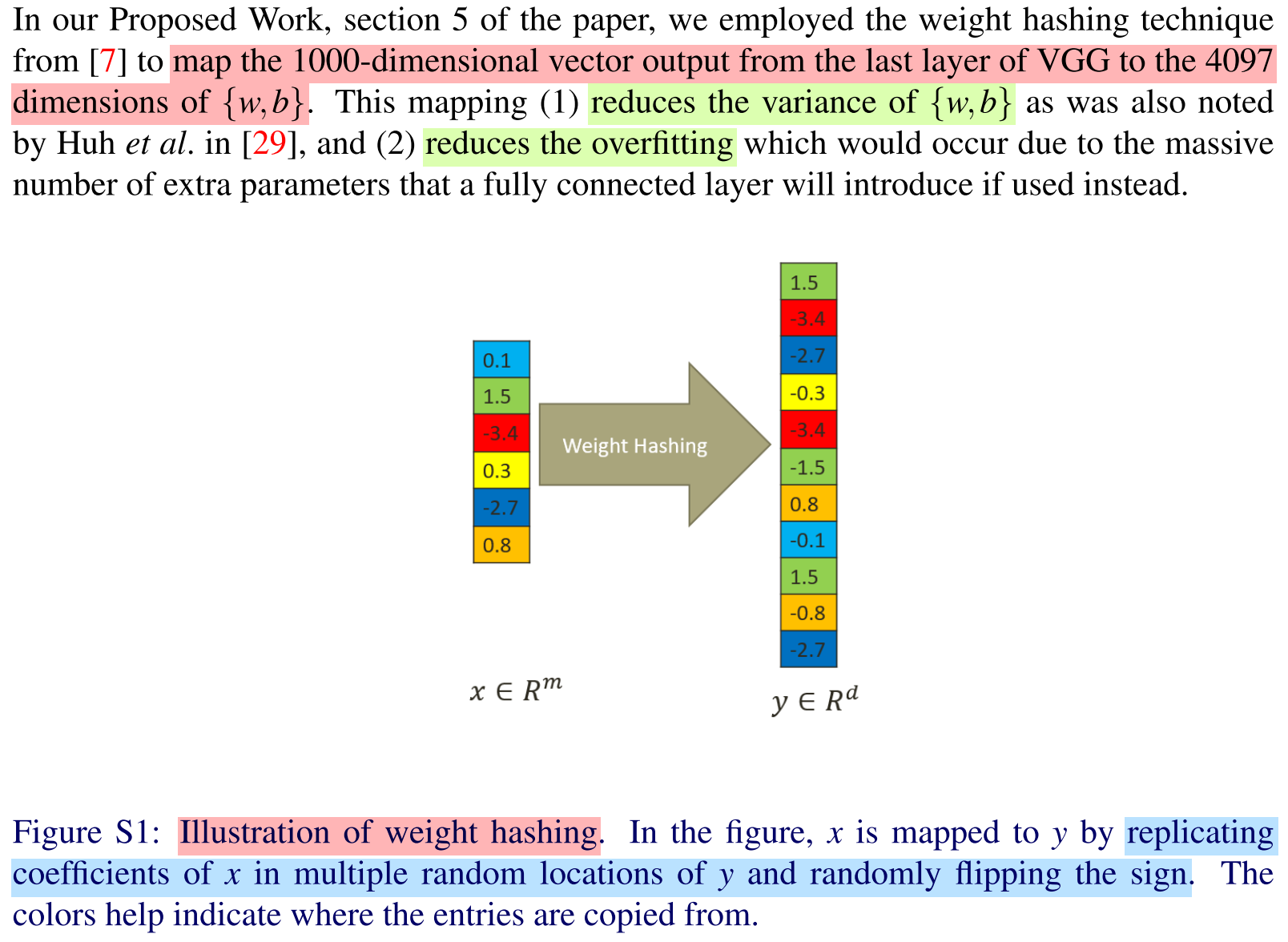
Experiments
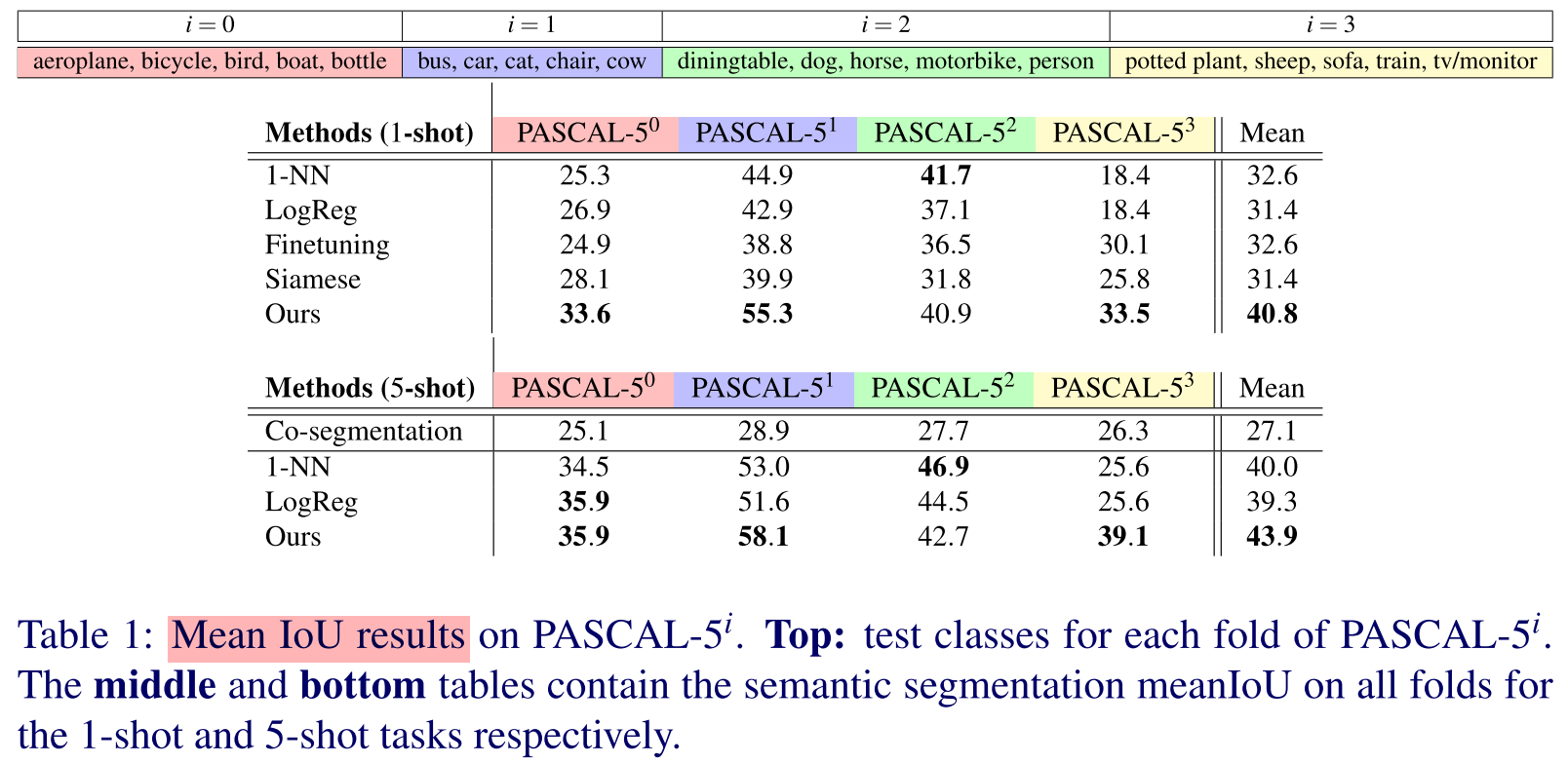

Code
[Updating]
Note
- It takes inspiration from few-shot learning and firstly proposes a novel two-branched approach to one-shot semantic segmentation.
References
[1] Shaban A, Bansal S, Liu Z, et al. One-shot learning for semantic segmentation[J]. arXiv preprint arXiv:1709.03410, 2017.
[2] OSLSM. https://github.com/lzzcd001/OSLSM.