PV-RCNN[1] is a 3D Object Detection framework to integrate
3D voxel CNNandPointNet-based set abstractionto learn more discriminative point cloud features. The most contributions in this papar is two-stage strategy including thevoxel-to-keypoint3D scene encoding and thekeypoint-to-gridRoI feature abstraction. There are some details of reading and implementing it.
Contents
Paper & Code & note
Paper: PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection(CVPR 2020 paper)
Code: PyTorch
Note: Mendeley
Paper
Abstract

- They present PointVoxel-RCNN(PV-RCNN) for accurate 3D object detection from point clouds.
- It summarizes the 3D scene with a 3D voxel CNN into a small set of
keypointsvia a novel voxel set abstraction(VSA) module.- RoI-grid pooling is proposed to abstract proposal-specific features from the keypoints to the RoI-
grid points, the RoI-grid feature points encode much richer context information.- It surpasses state-of-the-art 3D detection.
Problem Description

- The
grid-based methodsgenerally transform the irregular point clouds to regular representations such as 3D voxels, they are more computationally efficient.- The
point-based methodsdirectly extract discriminative features from raw point clouds for 3D detection, they could achieve larger receptive field.
Problem Solution

- They integrated these two types. The
voxel-based operationefficiently encodes multi-scale feature representations,PointNet-based set abstraction operationpreserves accurate location information with flexible receptive field.- The voxel CNN with
3D sparse convolutionis adopted for voxel-wise feature learning and accurate proposal generation.- A small set of
keypointsare selected by the furtherest point sampling (FPS) to summarize the overall 3D information from the voxel-wise features.PointNet-based set abstractionfor summarizing multi-scale point cloud information.
Conceptual Understanding
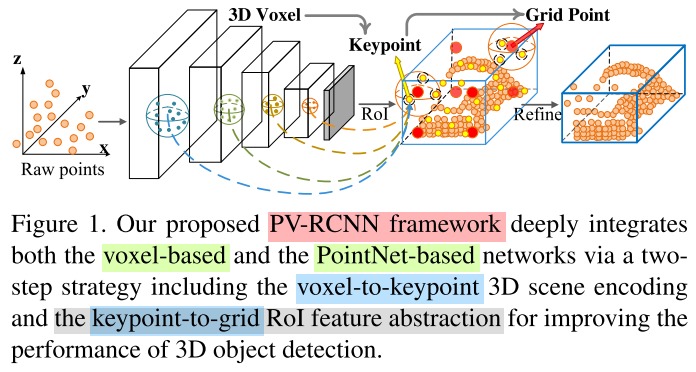
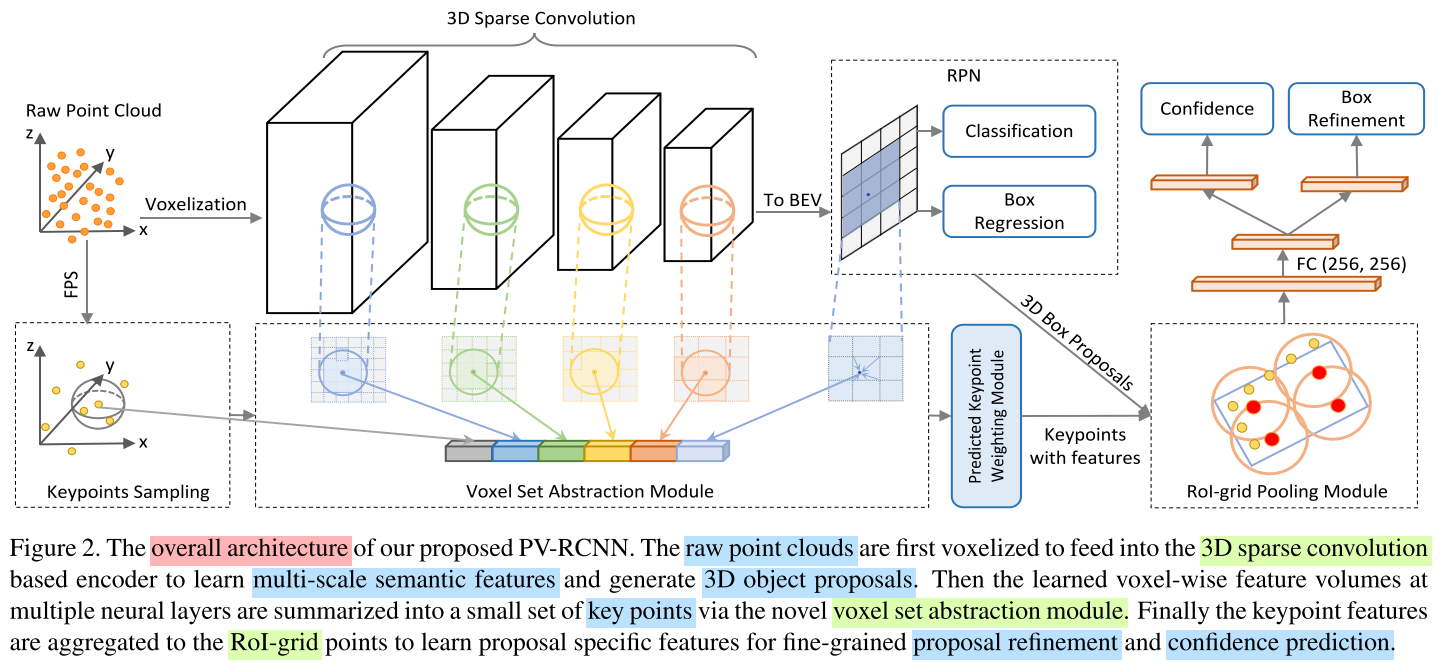
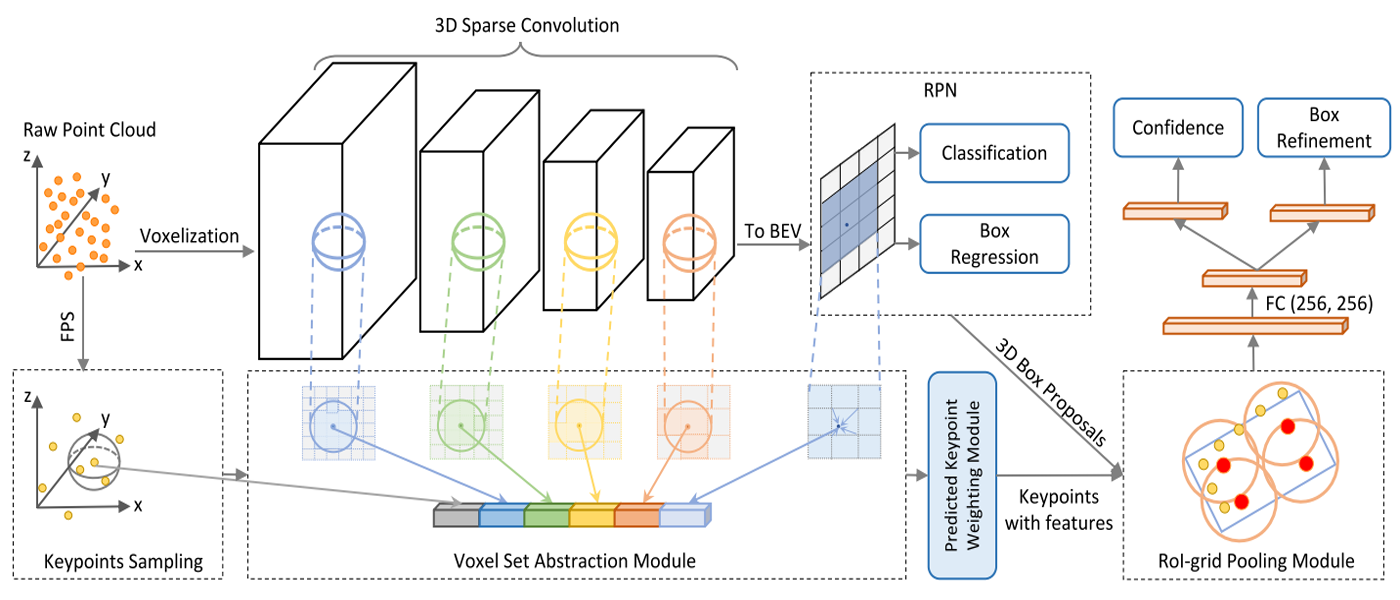
- 3D Sparse Convolution: Input the
raw point cloudsto learnmulti-scale semantic featuresand generate3D object proposals.- Voxel Set Abstraction: the learned
voxel-wise featurevolumes at multiple neural layers are summarized into a small set ofkey points.- RoI-grid Pooling: the
keypointfeatures are aggregated to the RoI-grid points.
Core Conception
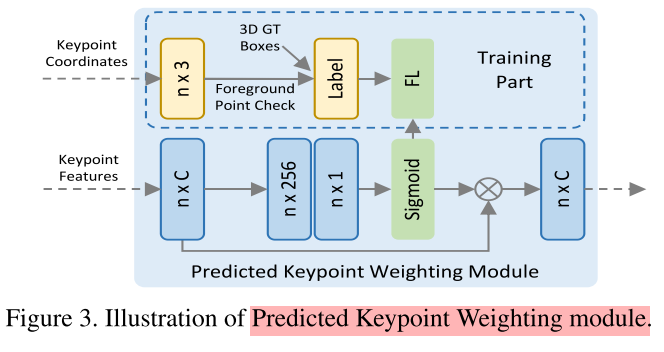
Predicted Keypoint Weighting
RoI-grid Pooling
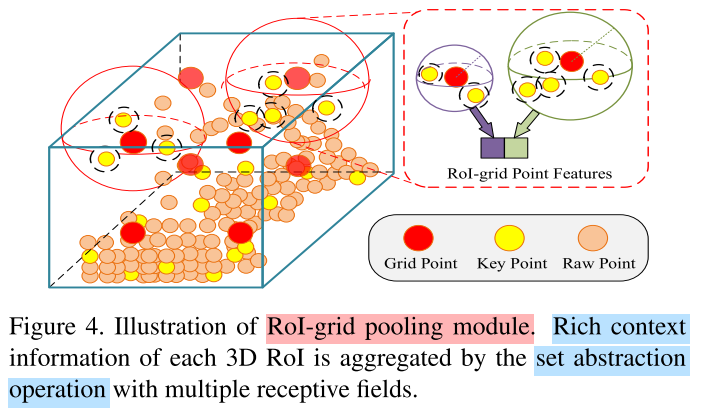
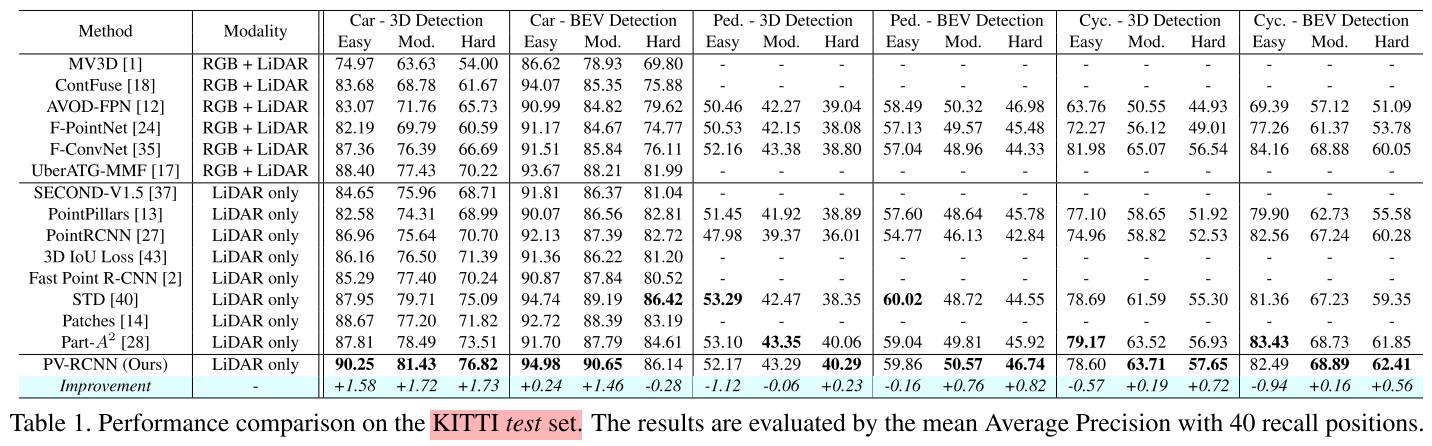
Experiments
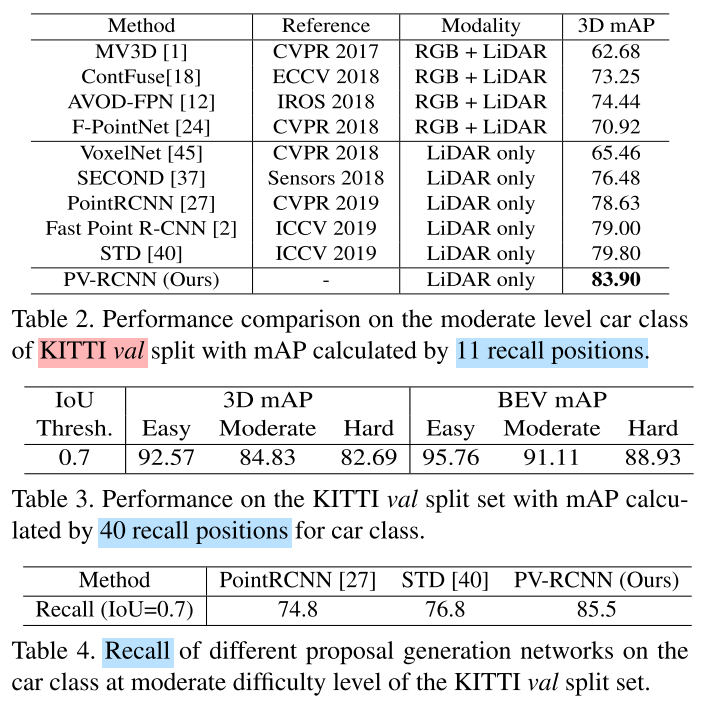

Code
[Updating]
Note
- Provide more
accurate detectionsby point cloud features.- Integrate it to
multiple object trackingframework.
References
[1] Shi S, Guo C, Jiang L, et al. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 10529-10538.
[2] PV-RCNN. https://github.com/sshaoshuai/PV-RCNN
[3] vision3d. https://github.com/jhultman/vision3d