TSDM[1] is a RGB-D tracker which use depth information to pretreatment and fuse information to pro-processing. It is composed of a
Mask-generator(M-g),SiamRPN++and aDepth-refiner(D-r). There are some details of reading and implementing it.
Contents
Paper & Code & note
Paper: TSDM: Tracking by SiamRPN++ with a Depth-refiner and a Mask-generator(arXiv 2020 paper)
Code: PyTorch
Note: Mendeley
Paper
Abstract

- Depth information provides informative cues for foreground-background separation and target bounding box regression.
- Few trackers have used depth information to play the important role aforementioned due to the lack of a suitable model.
- In this paper, a RGB-D tracker named TSDM is proposed, The
M-ggenerates the background masks, and updates them as the target 3D position changes. TheD-roptimizes the target bounding box estimated bySiamRPN++, based on the spatial depth distribution difference between the target and the surrounding background.- It outperforms the state-of-the-art on the PTB and VOT.
Problem Description

- The main obstacle is that the tracker requires constant information (such as color), but the target
depth distribution may changea lot when the target moves.
Problem Solution


- Depth mudules:
M-gandD-rcan overcome the obstacle above and make use of depth information effectively.- Data augmentation: it helps
retrain SiamRPN++to work better with the M-g module.
Conceptual Understanding
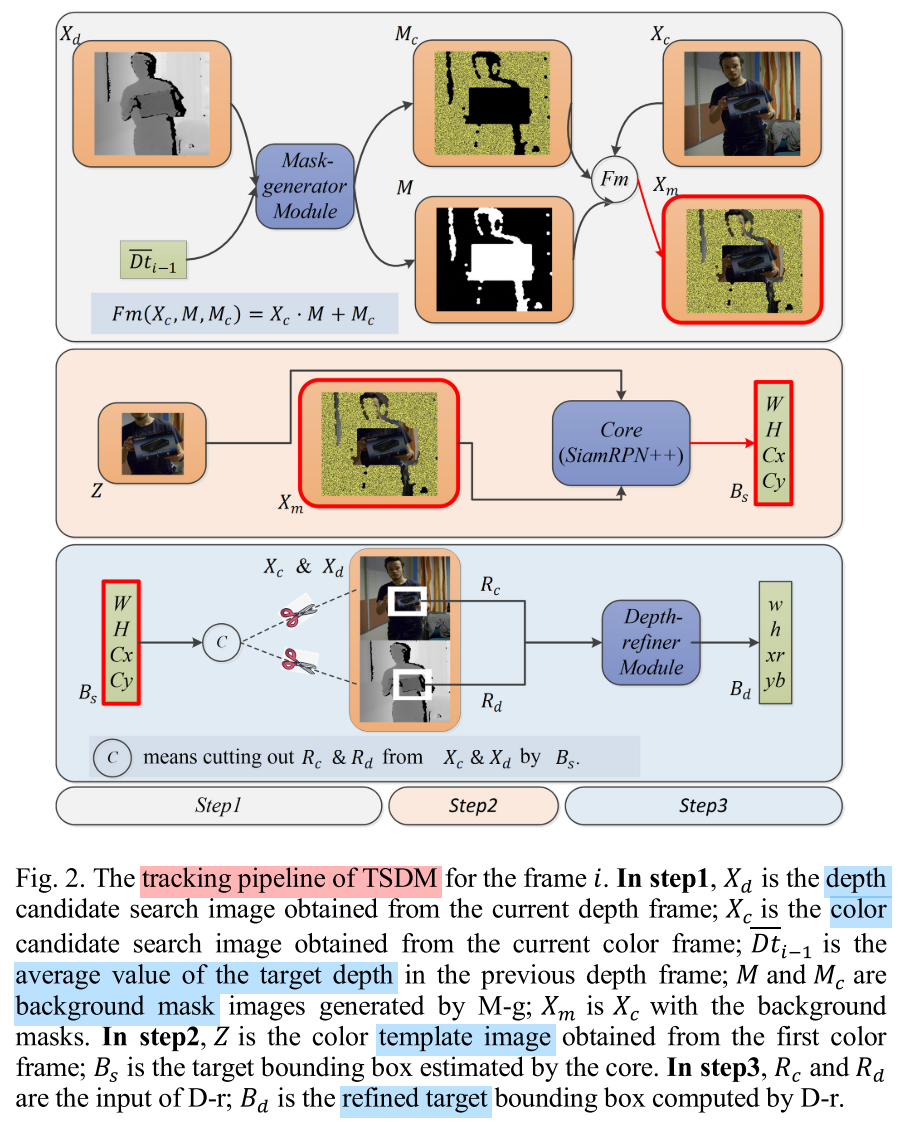
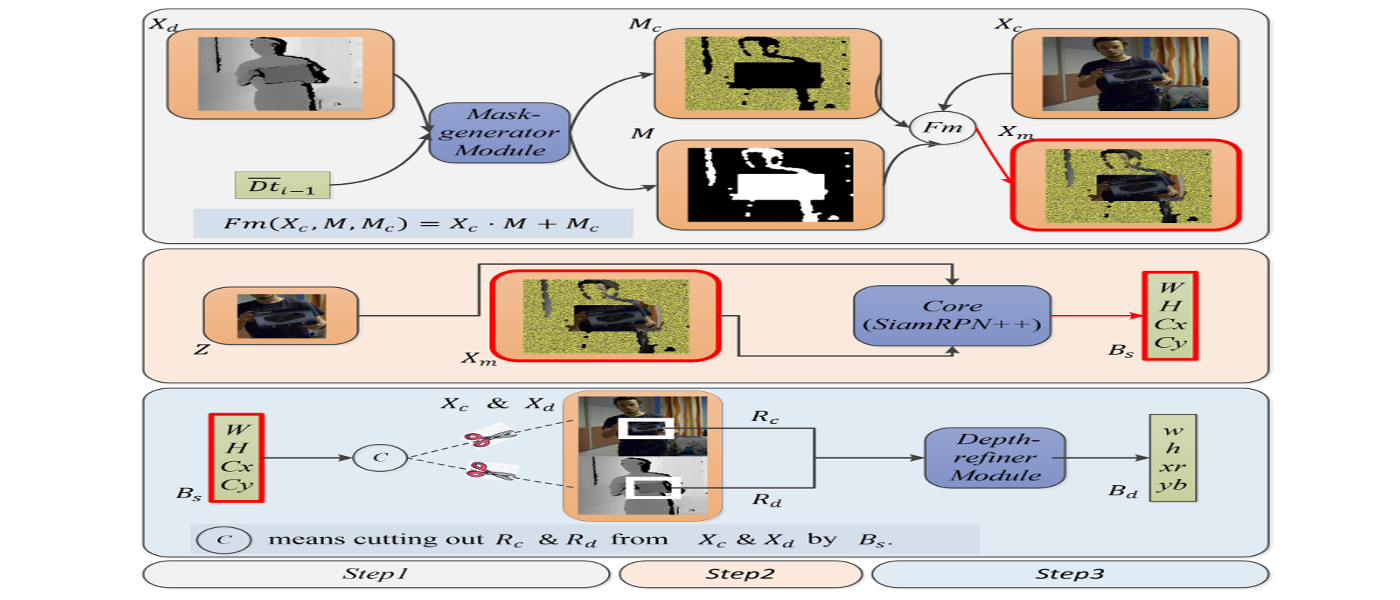
- Mask-generator: Input $X_d$ and $\overline{Dt_{i-1}}$ into M-g to get $M$ and $M_c$, then use $F_m(\cdot)$ to get $X_m$.
- SiamRPN++: Input $Z$ and $X_m$ into the core, then outputs the target bounding box $B_s$ ($W,H,C_x,C_y$).
- Depth-refiner: Cut out $R_c$ and $R_d$ from $X_c$ and $X_d$ by $B_s$ respectively. Then input $R_c$ and $R_d$ into D-r to get the refined target bounding box $B_d$ ($w,h,xr,yb$).
Core Conception
Mask-generator
- M-g generates two background mask images, $M$ is a 2-value image for clearing out the background of $X_c$, and $M_c$ is a color image for coloring the background of $X_c$.
- $M_c$ color selection: $M_c$ enhances the target background difference to make the target template matching easier.
- M-g stop-restart strategy: M-g should automatically stop to avoid masking the real target when a transient tracking drift happens.
- M-g simulated data augmentation: it used to generate enough training samples ($X_m$) to retrain the SiamRPN++.
SiamRPN++
- It takes an image pair ($Z,X$) as input and outputs the target bounding box in the current frame, as: $f(Z,X)=\phi(Z)\ast\phi(X)$.
- More details of SiamRPN++ can be found in previous blog [SiamRPN++][2].
Depth-refiner
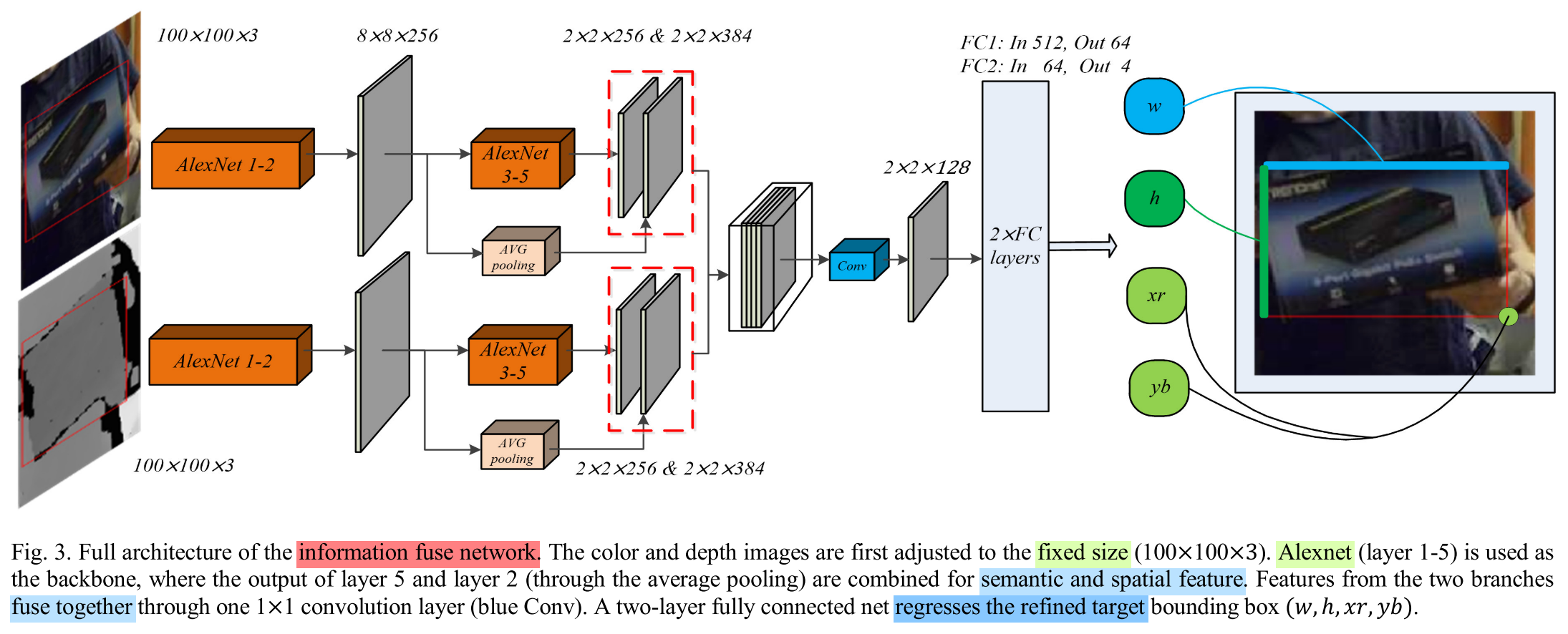
- The bounding box estimated by the core contains the whole target, D-r improve the tracker performance just by
cutting out no-target area.- Information Fusion Network: It uses
depthinformation to optmize the target state, andcolorinformation to overcomes the slight color-depth mismatch. The full architecture is as follows:
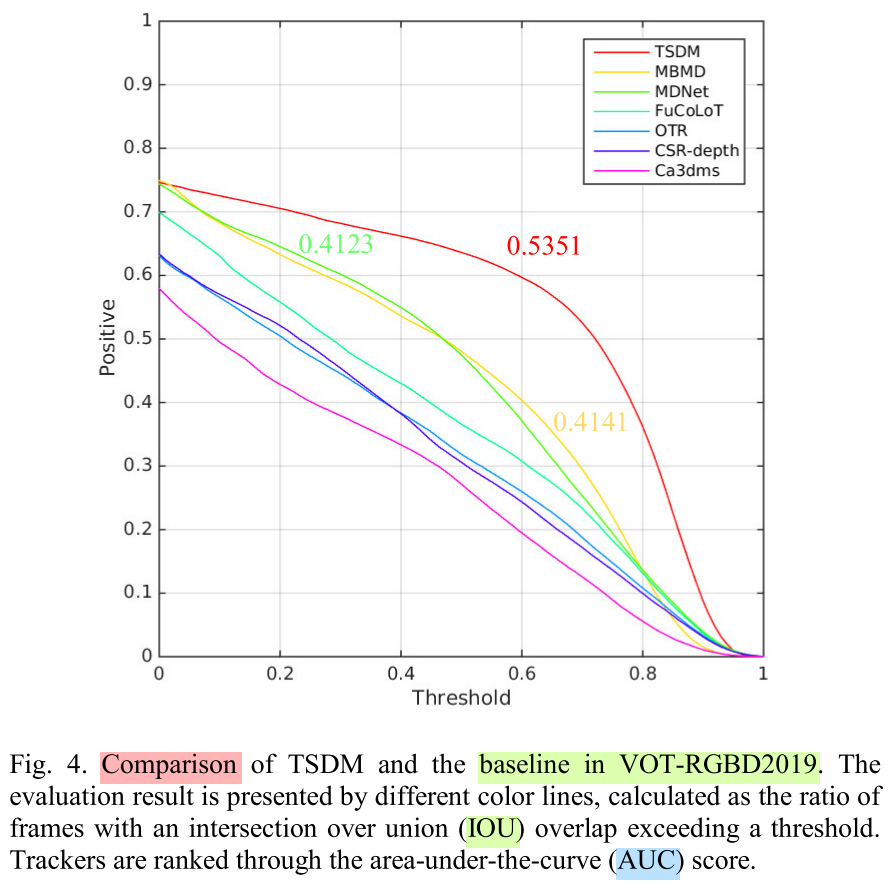
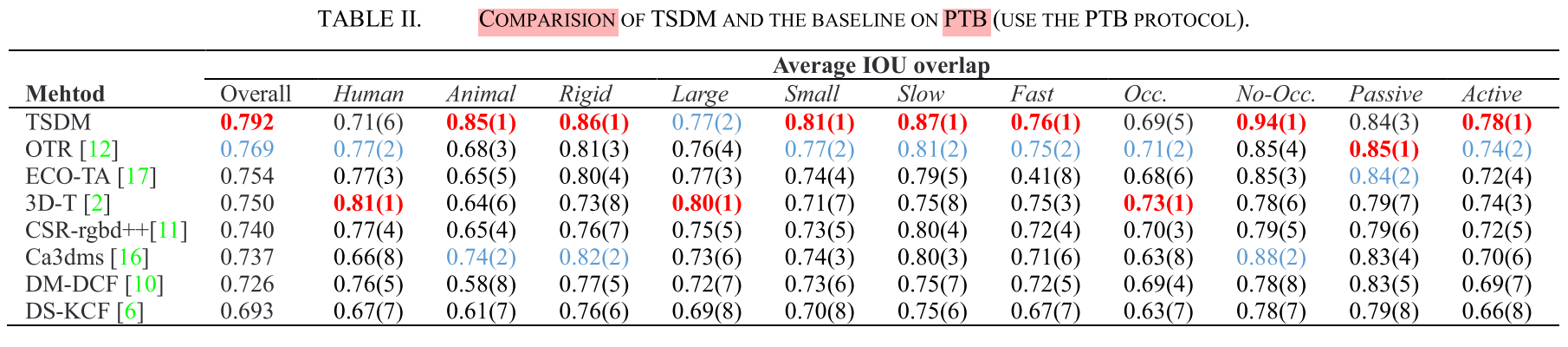
Experiments

Code
The complete code can be found in here with citing TSDM[3].
[Updating]
Note
How to use depth information on MOT tasks, detection or re-ID.
References
[1] ZHAO, Pengyao, et al. TSDM: Tracking by SiamRPN++ with a Depth-refiner and a Mask-generator. arXiv preprint arXiv:2005.04063, 2020.
[2] Gojay. “SiamRPN++.” https://gojay.top/2020/05/09/SiamRPN++/
[3] TSDM. https://github.com/lql-team/TSDM