Image Transformer[1] is a sequence modeling formulation of image generation generalized by
Transformer, which restricting the self-attention mechanism to attend to local neighborhoods, while maintaininglarge receptive field. There are some details of reading and implementing it.
Contents
Paper & Code & note
Paper: Image Transformer(2018 arXiv paper)
Code: [Code]
Note: Mendeley
Paper
Abstract

- Image generation has been successfully cast as an autoregressive sequence generation or transformation problem.
- In this work, they generalize the
Transformerto a sequence modeling formulation of image generation.- By restricting the self-attention mechanism to attend to local neighborhoods while maintaining
large receptive field.- outperform the current state of the art in image generation and super-resolution.
Problem Description

- Training RNNs(recurrent neural networks) to sequentially predict each pixel of even a small image is
computationallyvery challenging. Thus,parallelizablemodels that use CNNs(convolutional neural networks) such as the PixelCNN have recently received much more attention, and have now surpassed the PixelRNN in quality.- One disadvantage of CNNs compared to RNNs is their typically fairly
limited receptive field. This can adversely affect their ability to model long-range phenomena common in images, such as symmetry and occlusion, especially with a small number of layers.
Problem Solution

- self-attention can achieve a better
balance in the trade-offbetween the virtually unlimited receptive field of the necessarily sequentialPixelRNNand the limited receptive field of the much more parallelizablePixelCNNand its various extensions.
We.
- Image Transformer which is a model based entirely on a self-attention mechanism allows us to use significantly larger receptive fields than the PixelCNN.
- Increasing the size of the receptive field plays a significant role in experiments improvement.
Conceptual Understanding
Self-Attention

- Each self-attention layer computes a
d-dimensional representationfor each position.- it first compares the position’s current representation to other positions’ representations, obtaining an
attention distributionover the other positions.- This distribution is then used to
weight the contributionof the other positions’ representations to the next representation for the position.
Local Self-Attention

- Inspired by CNNs, they address this by adopting a notion of locality, restricting the positions in the
memory matrix Mto a local neighborhood around the query position.- They partition the image into query blocks and associate each of these with a larger
memory block.- The model attends to the same memory matrix, the self-attention is then computed for all query blocks in parallel.
Core Conception
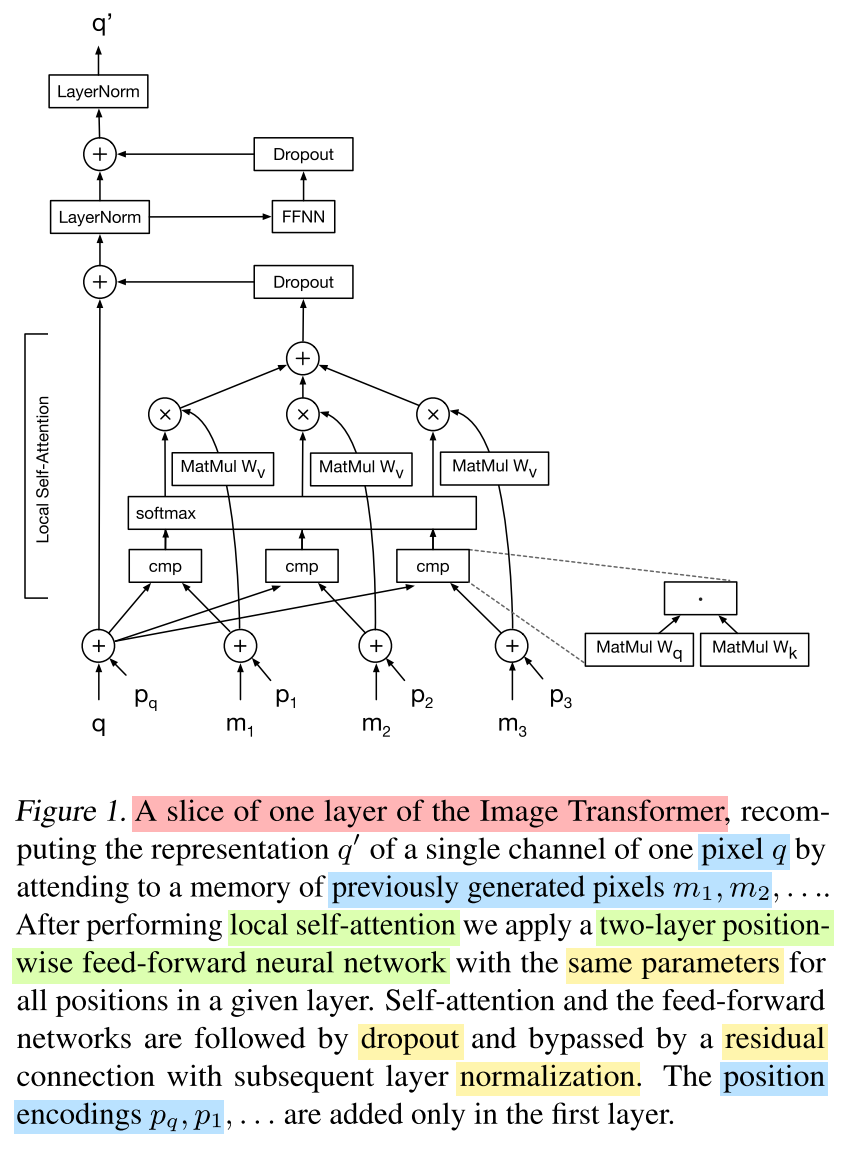
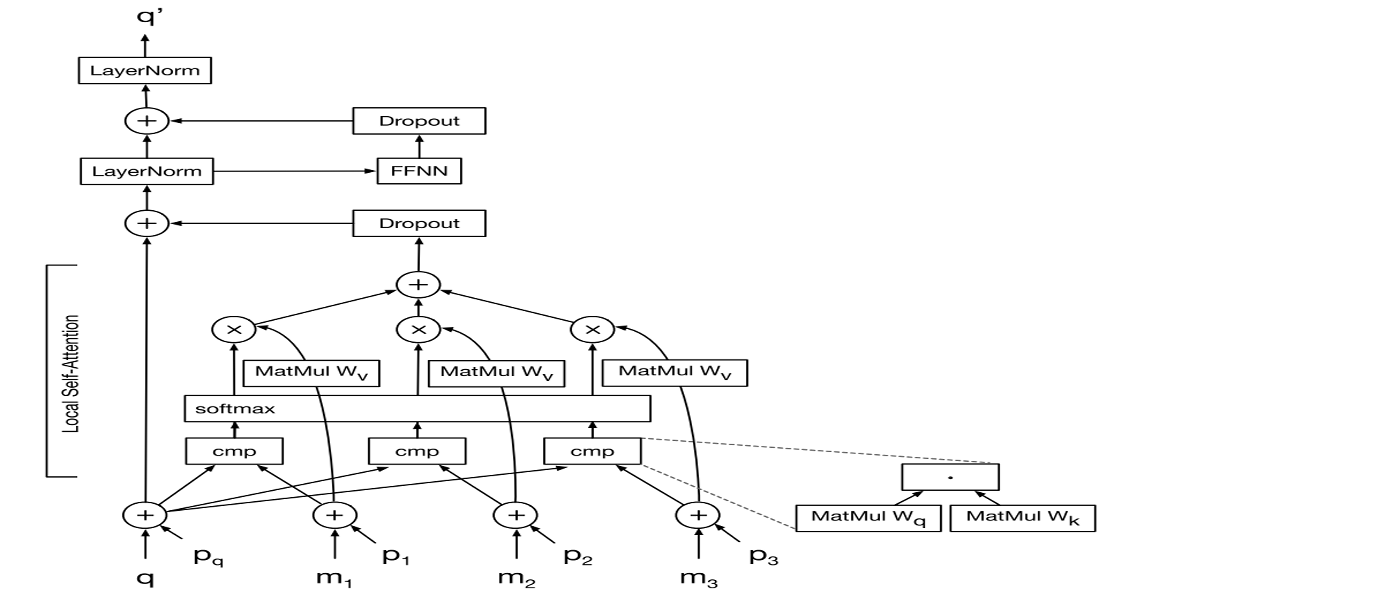
- Recomputing the representation $q’$ of a single channel of one pixel $q$ by attending to a memory of previously generated pixels $m_1,m_2,…$.
- After performing local self-attention we apply a two-layer position- wise feed-forward neural network with the
same parametersfor all positions in a given layer.- Self-attention and the feed-forward networks are followed by
dropoutand bypassed by aresidual connectionwith subsequentlayer normalization.
Experiments



Code
[Updating]
Note


- We further hope to have provided additional evidence that even in the light of GANs(generative adversarial networks), likelihood-based models of images is very much a promising area for further research.
- We would like to explore a broader variety of conditioning information including free-form text, and tasks combining modalities such as language-driven editing of images.
- Fundamentally, we aim to move beyond still images to video and towards applications in model-based
reinforcement learning.
References
[1] Parmar, Niki, et al. “Image transformer.” arXiv preprint arXiv:1802.05751 (2018).