SiamRPN++[1] is a novel Siamese network based tracker to adopt deep networks that broke strict
translation invariance. It performslayer-wiseanddepth-wiseaggregations to successfully trained aResNet-drivenSiamese tracker. There are some details of reading and implementing it.
Contents
Paper & Code & note
Paper: SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks(CVPR 2019 paper)
Code: PyTorch
Note: Mendeley
Paper
Abstract

- Siamese trackers formulate tracking as convolutional feature cross-correlation that still have an
accuracy gapto take advantage of features from deep networks.- This paper proved the core reason comes from the
lack ofstrict translation invariance, and break this restriction through a simple yet effective spatial aware sampling strategy.- They further proposed a new model architecture to perform layer-wise and depth- wise aggregations.
- It obtains currently the best results on five large tracking benchmarks.
Problem Description

Paddingin deep networks will destroy the strict translation invariance.RPNrequires asymmetrical features for classification and regression.
Problem Solution

- Sampling strategy: break the spatial
invariancerestriction.- Layer-wise feature aggregation: predict the similarity map from features learned at
multiple levels.- Depth-wise separable correlation: produce multiple similarity maps associated with different semantic meanings to
reduces the parameter number.
Conceptual Understanding

- Hypothesis: the violation of strict translation invariance will lead to a
spatial bias.- Experiments: targets are placed in the center with
different shift rangesin sepreate training experiments.- Results: a strong center bias is learned, increasing shift ranges could
learn more areato alleviate it.
Core Conception
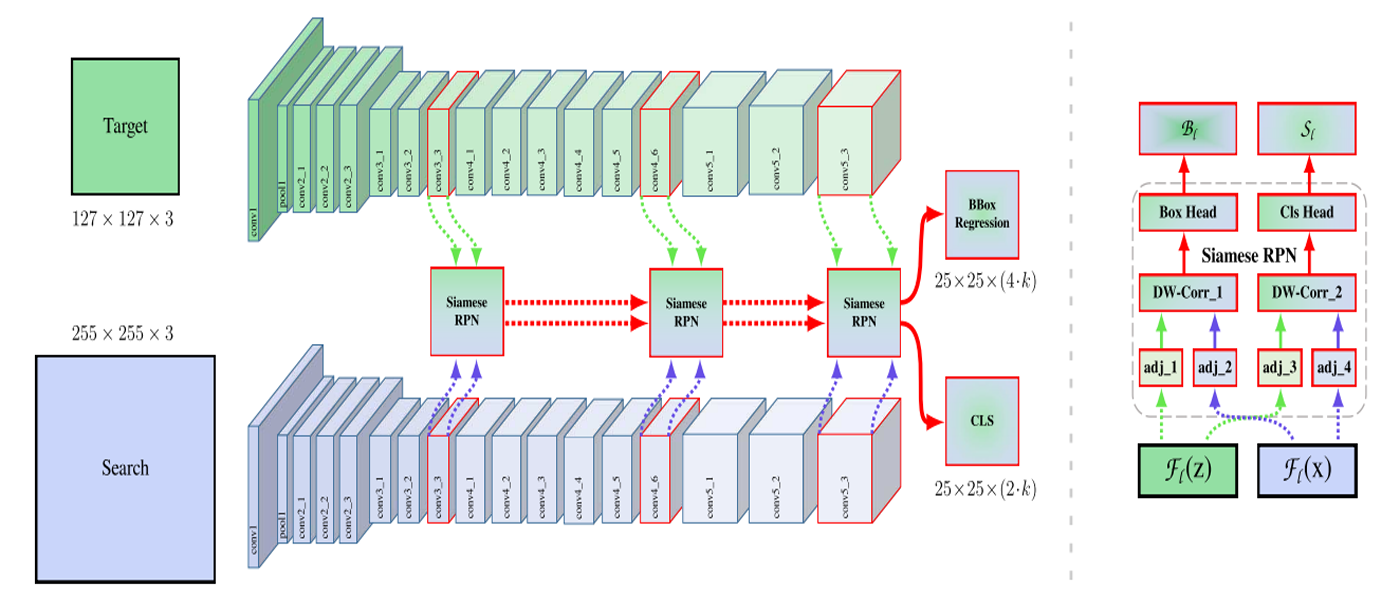
Layer-wise Aggregation

- They explore multi-level features both low level and semantic information that extracted from the last three residual block, refering these outputs as $F_3(z)$, $F_4(z)$, and $F_5(z)$.
- The output sizes of the three RPN modules have the same spatial resolution, weighted sum is adopted directly on the RPN output.
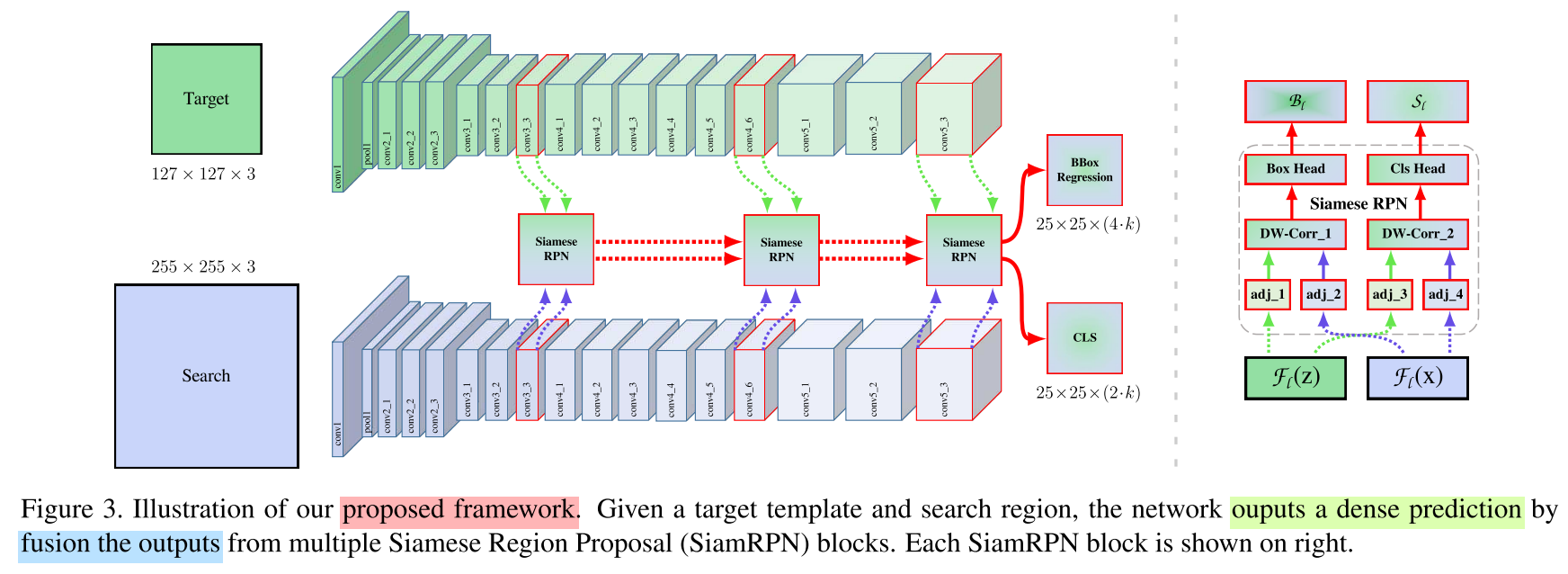
Depth-wise Cross Correlation
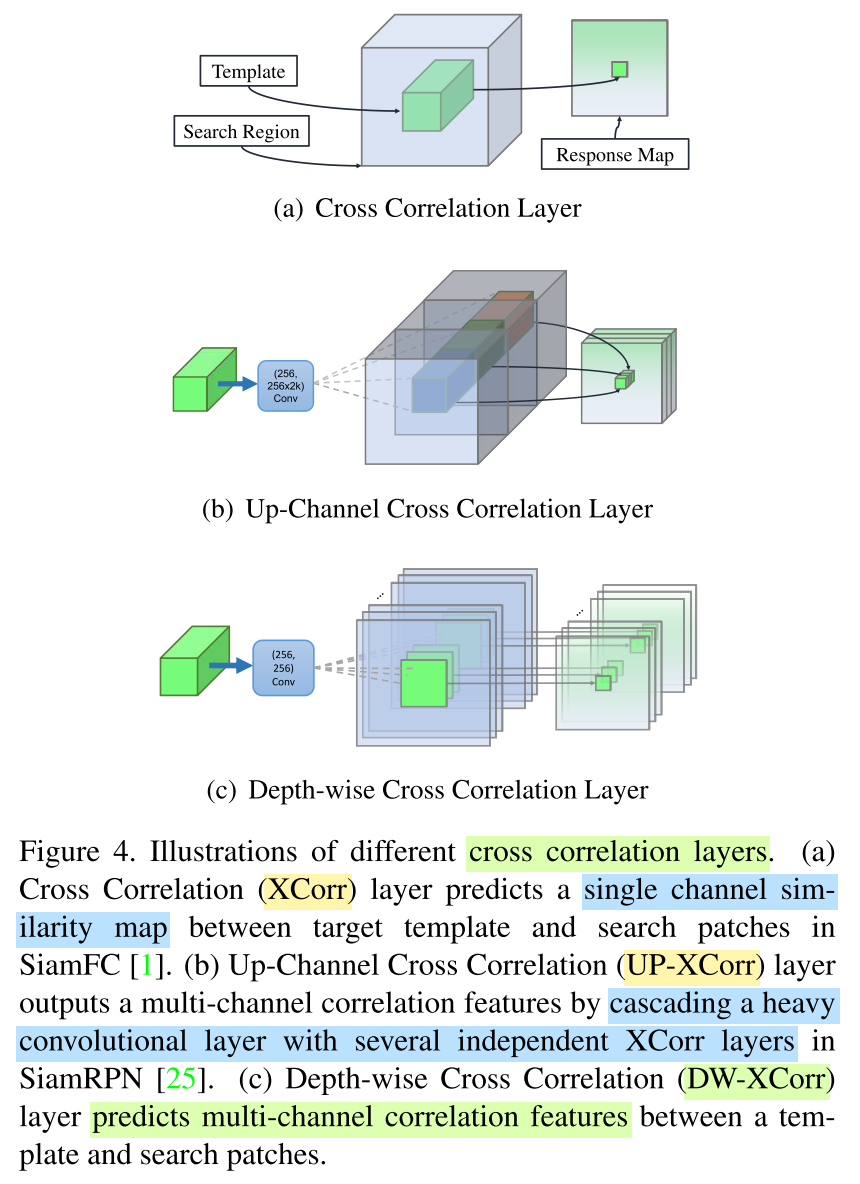

- A conv-bn block is adopted to make two feature maps with the same number of channels do the
correlation operation.- Another conv-bn-relu block is appended to
fuse different channeloutputs.
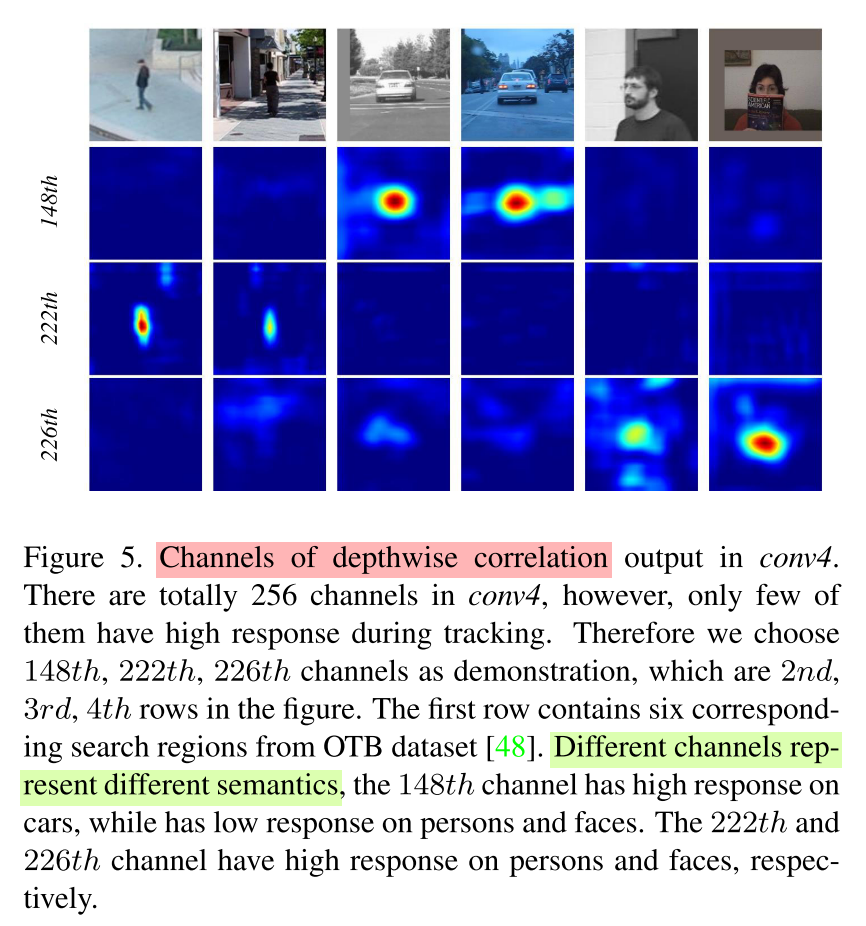
Furthermore, an interesting phenomena is that the objects in the same category have high response on same channels, while responses of the rest channels are suppressed. It can be comprehended as each channel represents some semantic information.
Experiments
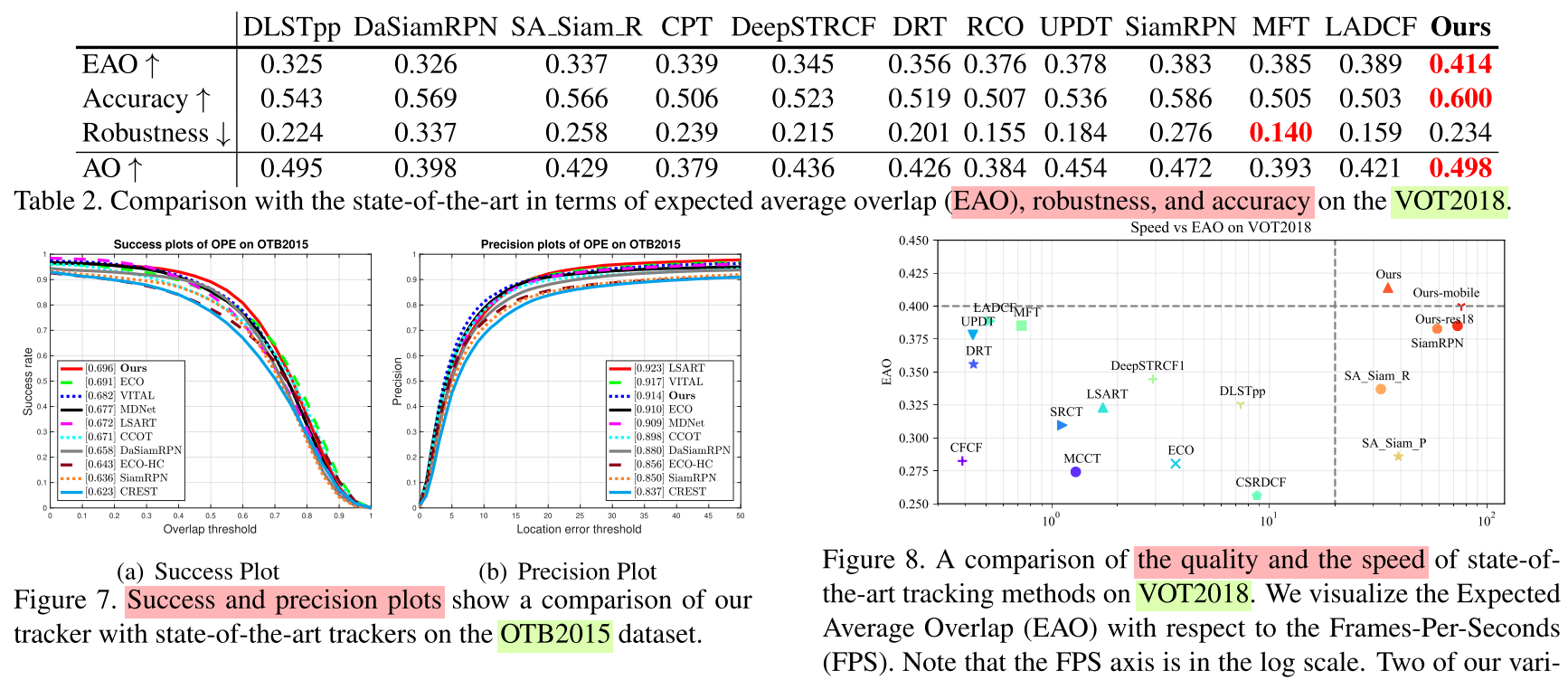
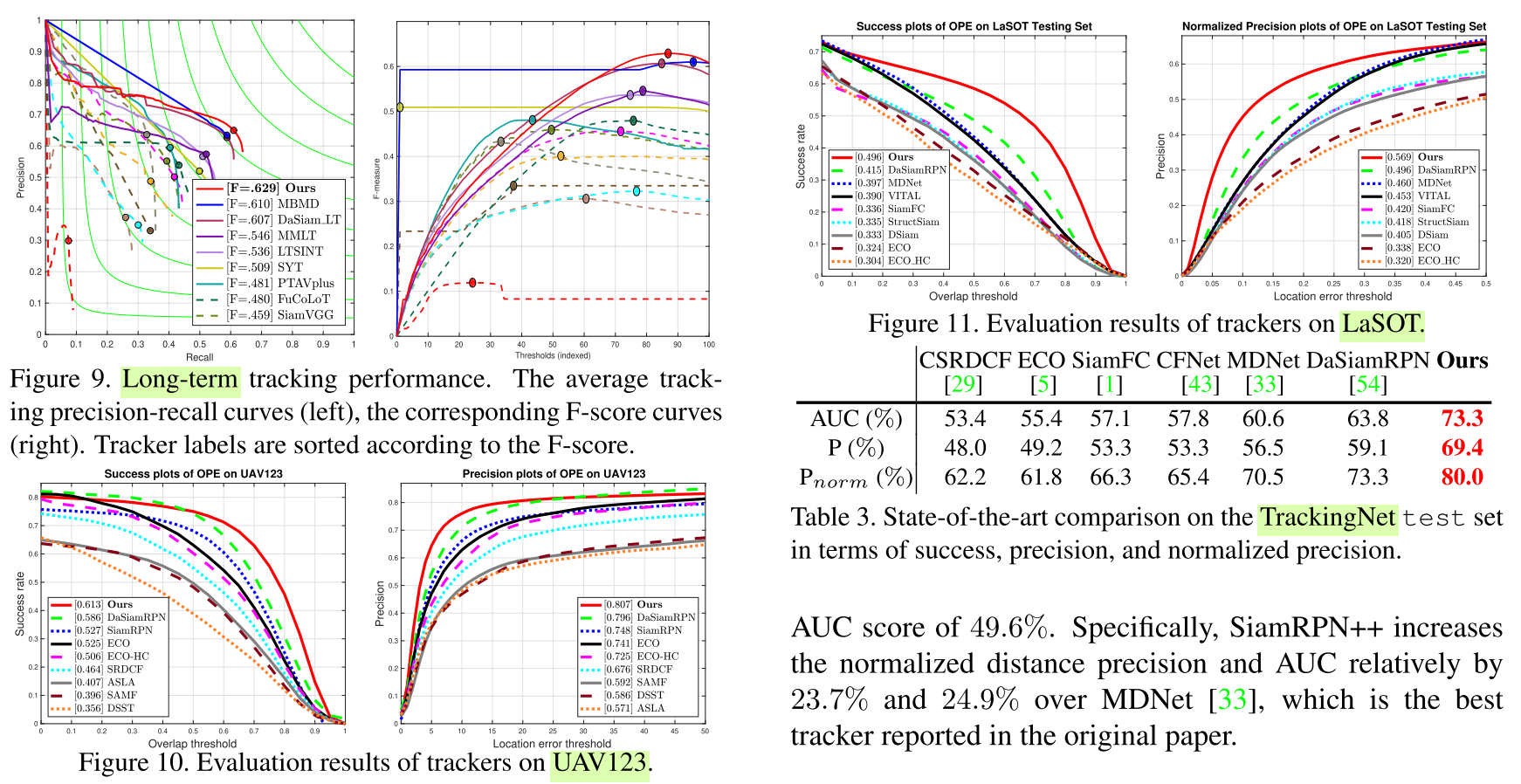
Code
The complete code can be found in [pysot][2].
Note
More details of SiamRPN++ and the like can be found in [3].
References
[1] LI, Bo, et al. Siamrpn++: Evolution of siamese visual tracking with very deep networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019. p. 4282-4291.
[2] pysot. https://github.com/STVIR/pysot.
[3] Erer Huang. “Overview of Siamese Network Methods.” https://zhuanlan.zhihu.com/p/66757733.